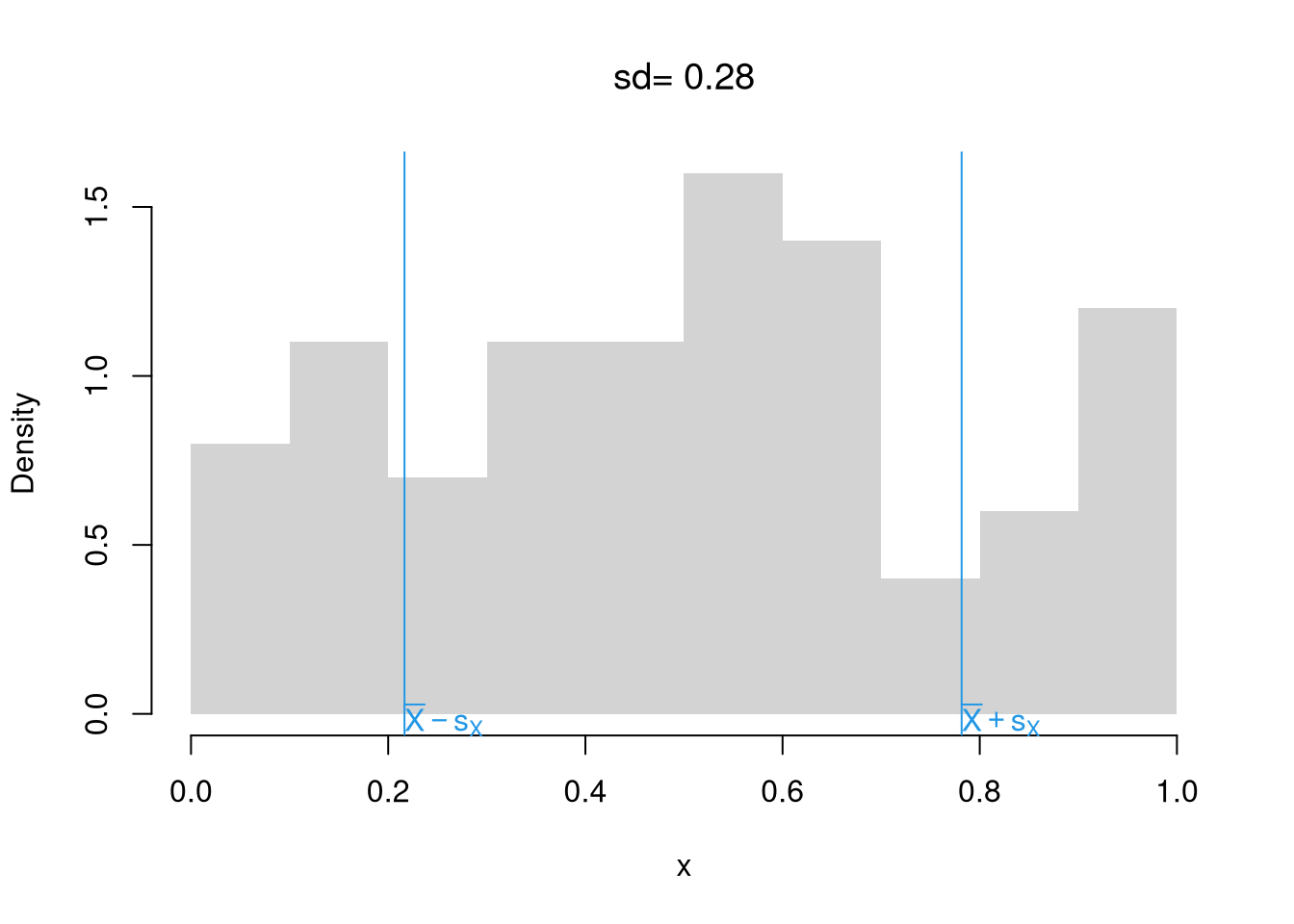
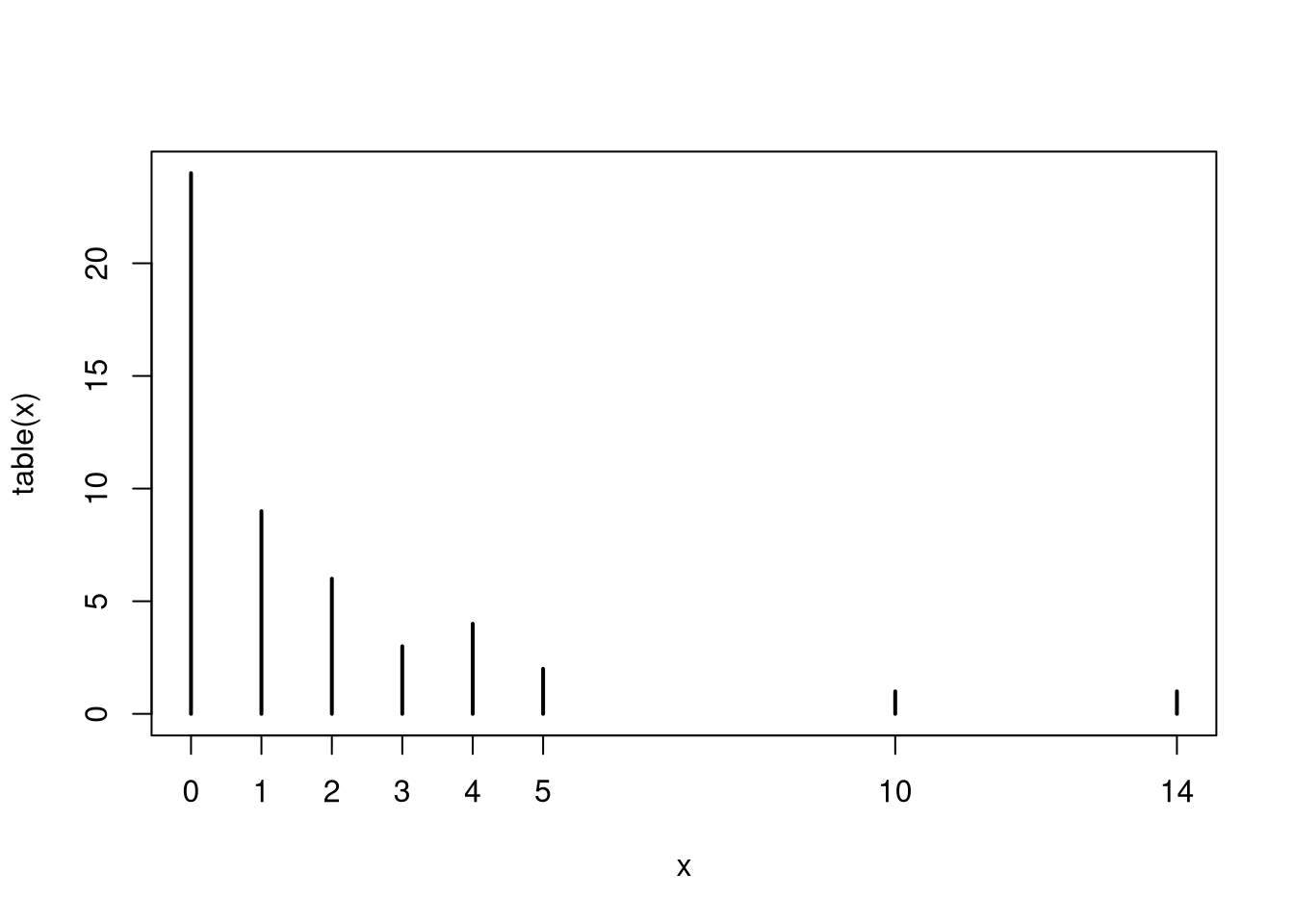
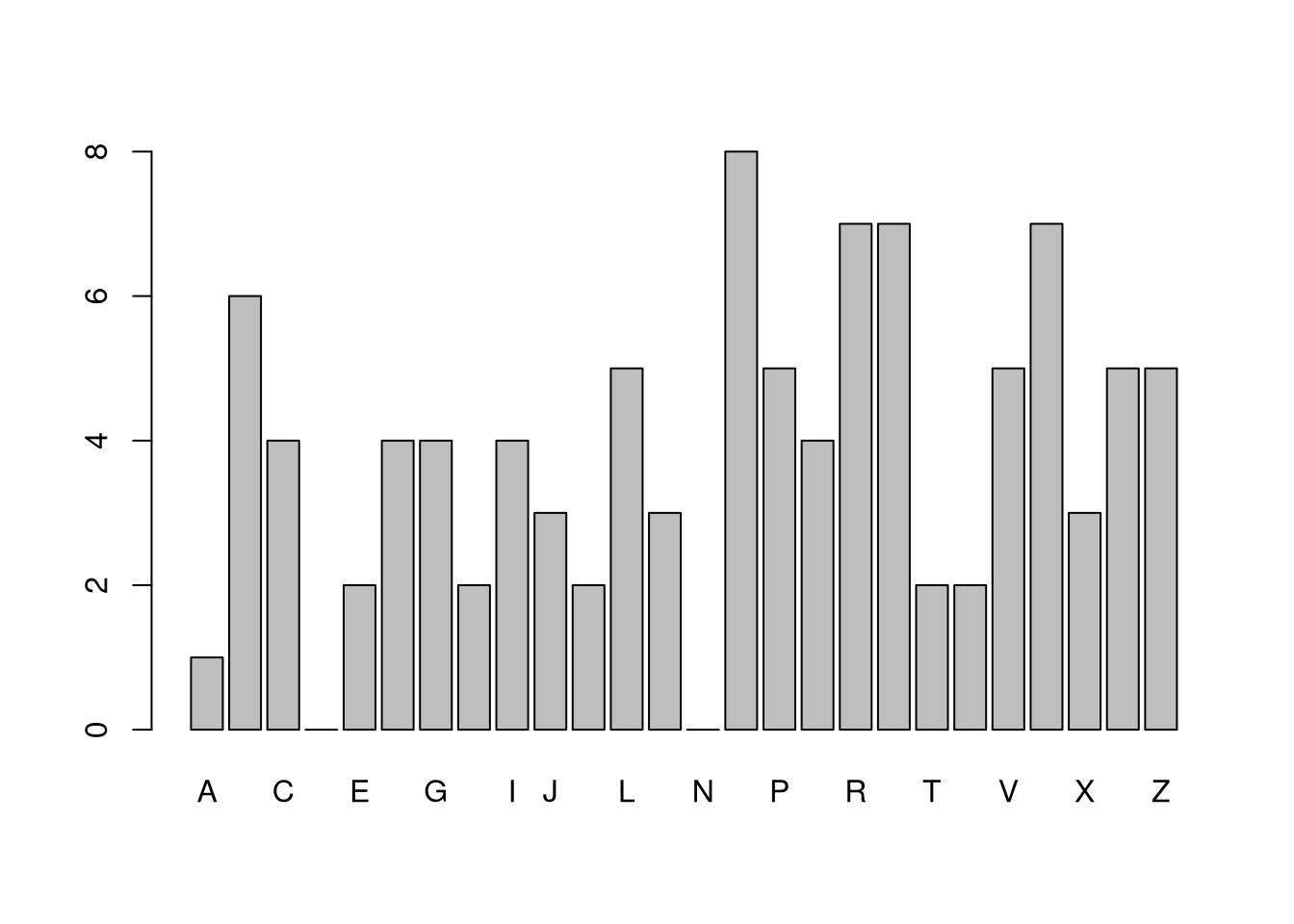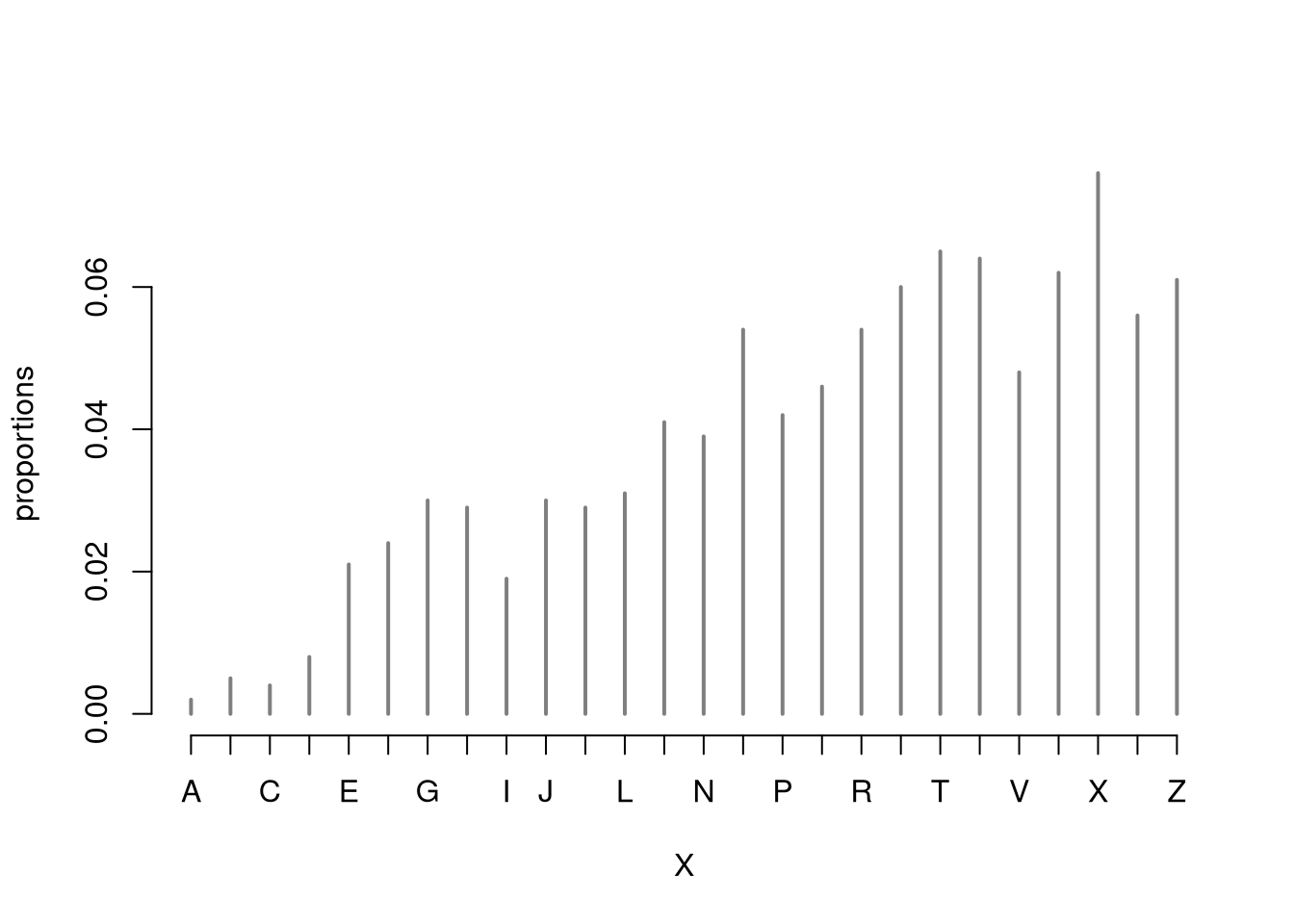We often summarize distributions with statistics: functions of data. The most basic way to do this is with summary, whose values can all be calculated individually.
Code
# A random sample (real data)X <- USArrests[,'Murder']summary(X)## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.800 4.075 7.250 7.788 11.250 17.400# A random sample (computer simulation)X <-runif(1000)summary(X)## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.0001031 0.2336437 0.4923672 0.4959324 0.7530332 0.9997765# Another random sample (computer simulation)X <-rnorm(1000) summary(X)## Min. 1st Qu. Median Mean 3rd Qu. Max. ## -3.53925 -0.67283 0.07031 0.02350 0.68904 3.77195
Together, the mean and variance statistics summarize the central tendency and dispersion of a distribution. In some special cases, such as with the normal distribution, they completely describe the distribution. Other distributions are better described with other statistics, either as an alternative or in addition to the mean and variance. After discussing those other statistics, we will return to the two most basic statistics in theoretical detail.
5.1 Mean and Variance
The mean and variance are the two most basic statistics that summarize the center and how spread apart the values are. As before, we represent data as vector \(\hat{X}=(\hat{X}_{1}, \hat{X}_{2}, ....\hat{X}_{n})\), where there are \(n\) observations and \(\hat{X}_{i}\) is the value of the \(i\)th one.
Mean.
Perhaps the most common statistic is the mean, which is the [sum of all values] divided by [number of values]; \[\begin{eqnarray}
\hat{M} &=& \frac{\sum_{i=1}^{n}\hat{X}_{i}}{n},
\end{eqnarray}\] where \(\hat{X}_{i}\) denotes the value of the \(i\)th observation.
Note
For example, a dataset of \(\{1,4,10\}\) has a mean of \([1+4+10]/3=5\).
Code
X <-c(1,4,10)sum(X)/length(X)## [1] 5mean(X)## [1] 5
Code
# compute the mean of a random sampleX1 <- USArrests[,'Murder']X1_mean <-mean(X1)X1_mean## [1] 7.788# visualize on a histogramhist(X1, border=NA, main=NA)abline(v=X1_mean, col=2, lwd=2)title(paste0('mean= ', round(X1_mean,2)), font.main=1)
Variance.
Perhaps the second most common statistic is the variance: the average squared deviation from the mean \[\begin{eqnarray}
\hat{V} &=&\frac{\sum_{i=1}^{n} [\hat{X}_{i} - \hat{M}]^2}{n}.
\end{eqnarray}\] The standard deviation is simply \(\hat{S} = \sqrt{\hat{V} }\), which can be interpreted as the average distance from the mean.
Note
For example, a dataset of \(\{1,4,10\}\) has a mean of \([1+4+10]/3=5\). The variance is \([(1-5)^2+(4-5)^2+(10-5)^2]/3=14\) and the standard deviation is \(\sqrt{14}\).
Code
X <-c(1,4,10)X_mean <-mean(X)X_var <-mean( (X - X_mean)^2 )sqrt(X_var)## [1] 3.741657
Note that a “corrected version” is used by R and many statisticians: \(\hat{V}' =\frac{\sum_{i=1}^{n} [\hat{X}_{i} - \hat{M}]^2}{n-1}\) and \(\hat{S}' = \sqrt{\hat{V}'}\). In this class, we use the “unocorrect version” as defined previously. There is hardly any difference when \(n\) is large: e.g., \(\frac{1}{n}\approx \frac{1}{n-1}\) for \(n=100,000\).
A general rule of applied statistics is that there are multiple ways to measure something. Mean and Variance are measurements of Center and Spread, but there are others that have different theoretical properties and may be better suited for your dataset.
Medians and Absolute Deviations.
We can use the Median as a “robust alternative” to means that is especially useful for data with asymmetric distributions and extreme values. Recall that the \(q\)th quantile is the value where \(q\) percent of the data are below and (\(1-q\)) percent are above. The median (\(q=.5\)) is the point where half of the data is lower values and the other half is higher. This means that median is not sensitive to extreme values (whereas the mean is).
# For discrete numbers# X <- rgeom(50, .4)#proportions <- table(X)/length(X)#plot(proportions, ylab='proportion')
Note
Examine robustness to an extreme value
Code
X_extreme <-c(X, 1000) # add one extreme value#par(mfrow=c(1,2)) # visualize side-by-side#hist(X)#hist(X_extreme)# Which measures of central tendency are robust# to a single extreme value?mean(X)## [1] 2.484768mean( X_extreme )## [1] 22.04389quantile(X, prob=0.5)## 50% ## 1.963428quantile(X_extreme, prob=0.5)## 50% ## 2.025766
We can also use the Interquartile Range or Median Absolute Deviation as an alternative to variance. The difference between the first and third quartiles (quantiles \(q=.25\) and \(q=.75\)) measure is range of the middle \(50%\) of the data, which is how the boxplot measures “spread”. The median absolute deviation is another statistic that also measures “spread”. \[\begin{eqnarray}
\tilde{M} &=& \text{Med}( \hat{X}_{i}) \\
\hat{\text{MAD}} &=& \text{Med}\left( | \hat{X}_{i} - \tilde{M} | \right).
\end{eqnarray}\]
Note
Compute the \(IQR\) statistic for the dataset \(\{-100,1,4,10,10\}\).
X <-c(-100,1,4,10,10)# An intuitive alternative to sd(X), used in the boxplotquants <-quantile(X, probs=c(.25,.75))quants[2]-quants[1]## 75% ## 9IQR(X)## [1] 9
Compute the \(\text{MAD}\) statistic for the dataset \(\{1,4,10\}\). First compute the median, \(\text{Med}(1,4,10)=1\). Then compute \(\text{Med}( |1-4|,~ |4-4|,~ |10-4| )= \text{Med}( 3, 0, 6 ) = 3\).
Code
X <-c(1,4,10)#Another alternative to sd(X)mad(X, constant=1)## [1] 3# Computationally equivalent# x_med <- quantile(X, probs=.5)# x_absdev <- abs(X -x_med)# quantile(x_absdev, probs=.5)
Note
Compare the robustness of various “spread” metrics to an extreme value
Note that there other “absolute deviation” statistics
Code
# sometimes seen elsewheremean( abs(X -mean(X)) )mean( abs(X -median(X)) )median( abs(X -mean(X)) )
Mode and Share Concentration.
Sometimes, none of the above work well. With categorical data, for example, distributions are easier to describe with other statistics. The mode is the most common observation: the value with the highest observed frequency. We can also measure the spread of the frequencies or concentration at the mode vs elsewhere.
Code
# Draw 3 Random Lettersx <- LETTERSx_probs <-seq(1, length(x))x_probs <- x_probs/sum(x_probs) # probs must sum to 1X <-sample(x, 1, prob=x_probs, replace=T)X## [1] "R"# Draw Random Letters 100 TimesX <-sample(x, 1000, prob=x_probs, replace=T)X <-factor(unlist(X), levels=LETTERS, ordered=F)proportions <-table(X)/length(X)plot(proportions, col=grey(0,0.5))
Central tendency and dispersion are often insufficient to describe a distribution. To further describe shape, we can compute skew and kurtosis to measure asymmetry and extreme values. There are many other statistics we could compute on an ad-hoc basis.
Skewness.
The skew statistic captures how asymmetric the distribution is by measuring the average cubed deviation from the mean, normalized the standard deviation cubed \[\begin{eqnarray}
\frac{\sum_{i=1}^{n} [\hat{X}_{i} - \hat{M}]^3 / n}{ s^3 }
\end{eqnarray}\]
Code
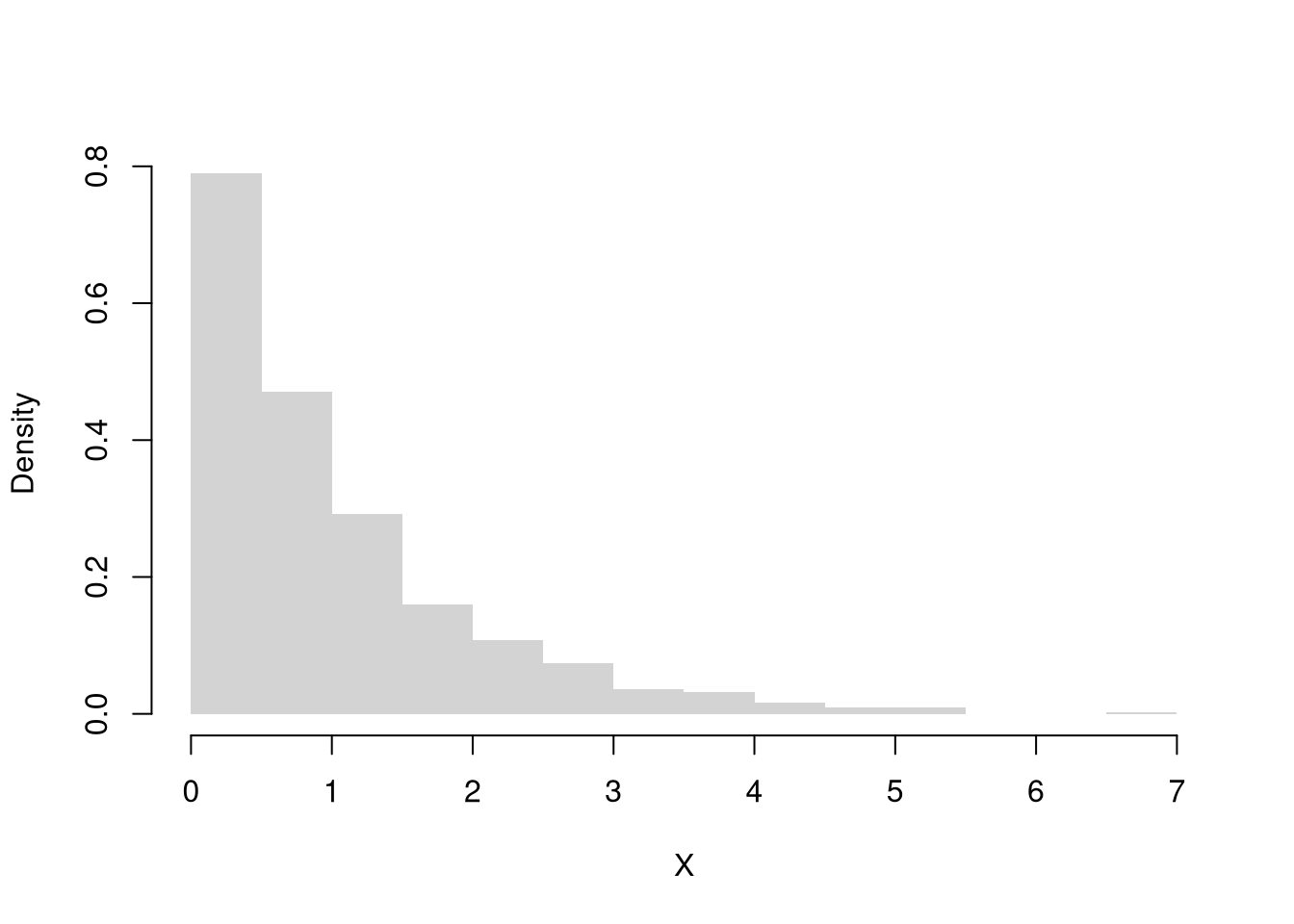
X <-rweibull(1000, shape=1)hist(X, border=NA, main=NA, freq=F, breaks=20)
We can automatically compare against the normal distribution, which has a skew of 0.
Kurtosis.
This statistic captures how many “outliers” there are like skew but looking at quartic deviations instead of cubed ones. \[\begin{eqnarray}
\frac{\sum_{i=1}^{n} [\hat{X}_{i} - \hat{M}]^4 / n}{ s^4 }.
\end{eqnarray}\] Some authors further subtract \(3\) to explicitly compare against the normal distribution (the normal distribution has a kurtosis of \(3\)).
Code
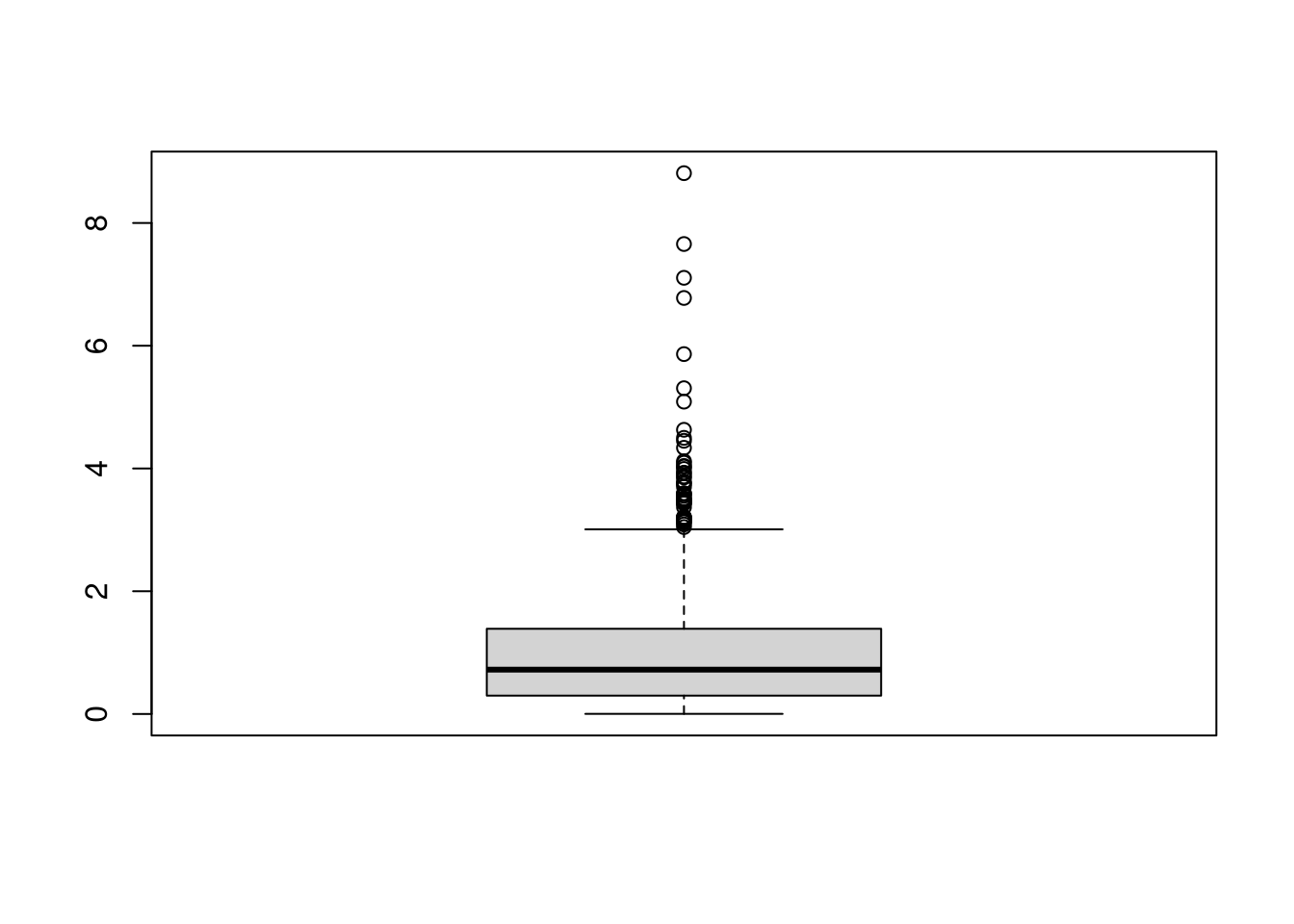
X <-rweibull(1000, shape=1)boxplot(X, main=NA)
Code
kurtosis <-function(X){ X_mean <-mean(X) m4 <-mean((X - X_mean)^4) s4 <-sd(X)^4 kurt <- m4/s4 excess_kurt <- kurt -3# compare against normalreturn(kurt)}kurtosis( rweibull(1000, shape=1) )## [1] 8.597539kurtosis( rweibull(1000, shape=10) )## [1] 3.392387
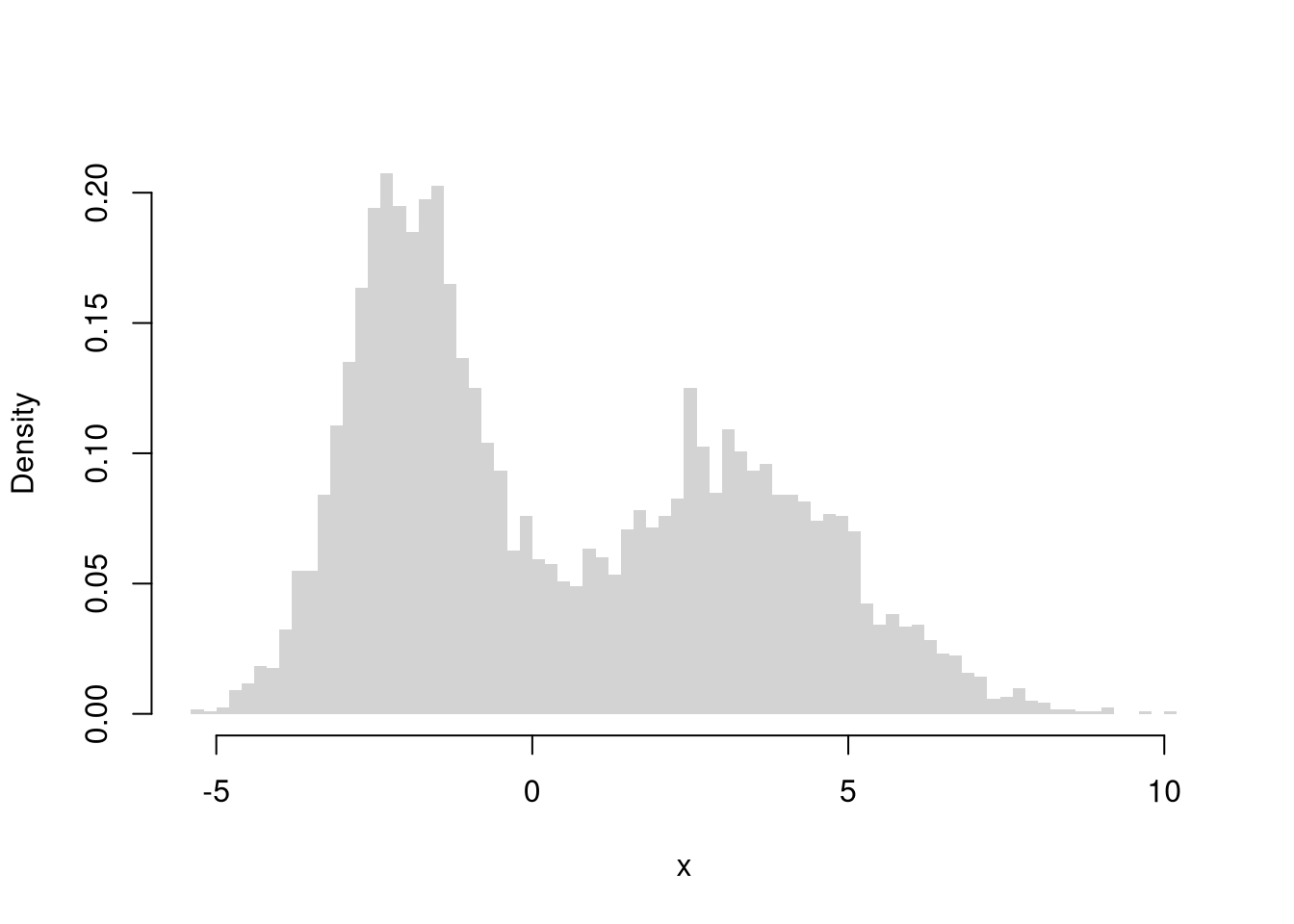
Clusters/Gaps.
You can also describe distributions in terms of how clustered the values are, including the number of modes, bunching, and many other statistics. But remember that “a picture is worth a thousand words”.
Code
# Complicated Random Variabler_ugly0 <-function(n, populationMean=c(-2, 3), populationVar=c(1, 4), prob=c(.5,.5)){# Which distribution is each observation coming from di <-sample(c(1,2), size=n, replace=TRUE, prob=prob)rnorm(n, mean=populationMean[di], sd=sqrt(populationVar)[di])}X <-r_ugly0(6000)hist(X, breaks=60,freq=F, border=NA,xlab="x", main='')
We will now dig a little deeper theoretically into the statistics we compute. When we know how the data are generated theoretically, we can often compute the theoretical value of the two most basic and often-used statistics: the mean and variance. To see this, we separately analyze how they are computed for discrete and continuous random variables.
Here, we denote \(X_{i}\) as a random variable that can take on specific values \(x\) from the sample space with known probabilities.
Discrete Random Variables.
If the sample space is discrete, we can compute the theoretical mean (or expected value) as \[\begin{eqnarray}
\mathbb{E}[X_{i}] = \sum_{x} x Prob(X_{i}=x),
\end{eqnarray}\] where \(Prob(X_{i}=x)\) is the probability the random variable \(X_{i}\) takes the particular value \(x\). Similarly, we can compute the theoretical variance as \[\begin{eqnarray}
\mathbb{V}[X_{i}] = \sum_{x} \left(x - \mathbb{E}[X_{i}] \right)^2 Prob(X_{i}=x).
\end{eqnarray}\] The theoretical standard deviation is \(\mathbb{s}[X_{i}] = \sqrt{\mathbb{V}[X_{i}]}\).
For example, consider a five-sided die with equal probability of landing on each side. I.e., \(X_{i}\) is a Discrete Uniform random variable with outcomes \(x \in \{1,2,3,4,5\}\). What is the theoretical mean? What is the variance and standard deviation? \[\begin{eqnarray}
\mathbb{E}[X_{i}] &=& 1\frac{1}{5} + 2\frac{1}{5} + 3\frac{1}{5} + 4\frac{1}{5} + 5\frac{1}{5} = 15/5 = 3\\
\mathbb{V}[X_{i}] &=& (1-3)^2\frac{1}{5} +
(2 - 3)^2\frac{1}{5} +
(3 - 3)^2\frac{1}{5} +
(4 - 3)^2\frac{1}{5} +
(5 - 3)^2\frac{1}{5} \\
&=& 2^2 \frac{1}{5} + 1^2\frac{1}{5} + 0^2 \frac{1}{5} + + 1^2\frac{1}{5} + 2^2 \frac{1}{5}
= (4 + 1 + 1 + 4)/5 = 10/5 = 2\\
\mathbb{s}[X_{i}] &=& \sqrt{2}
\end{eqnarray}\]
Code
# Computerized Way to Compute Meanx <-c(1,2,3,4,5)x_probs <-c(1/5, 1/5, 1/5, 1/5, 1/5)X_mean <-sum(x*x_probs)X_mean## [1] 3# Computerized Way to Compute SDXvar <-sum((x-X_mean)^2*x_probs)Xvar## [1] 2Xsd <-sqrt(Xvar)Xsd## [1] 1.414214# Verified by simulationXsim <-sample(x, prob=x_probs,size=10000, replace=T)mean(Xsim)## [1] 3.0066sd(Xsim)## [1] 1.427712
Note
For example, consider an unfair coin with a \(3/4\) probability of heads (\(x=1\)) and a \(1/4\) probability of tails (\(x=0\)) has a theoretical mean of \[\begin{eqnarray}
\mathbb{E}[X_{i}] = 0\frac{1}{4} + 1\frac{3}{4} = \frac{3}{4}
\end{eqnarray}\] and a theoretical variance of \[\begin{eqnarray}
\mathbb{V}[X_{i}] = [0 - \frac{3}{4}]^2 \frac{1}{4} + [1 - \frac{3}{4}]^2 \frac{3}{4}
= \frac{9}{64} + \frac{3}{64}
= \frac{12}{64}
= \frac{3}{16}.
\end{eqnarray}\] Verify both the mean and variance by simulation.
Code
# A simulation of many coin flipsx <-c(0,1)x_probs <-c(1/4, 3/4)X <-sample(x, 1000, prob=x_probs, replace=T)round( mean(X), 4)## [1] 0.754round( var(X), 4)## [1] 0.1857
Note
Consider a four-sided die with outcomes \(\{1,2,3,4 \}\) and corresponding probabilities \(\{ 1/8, 2/8, 1/8, 4/8 \}\) . What is the mean? \[\begin{eqnarray}
\mathbb{E}[X_{i}] = 1 \frac{1}{8} + 2 \frac{2}{8} + 3 \frac{1}{8} + 4 \frac{4}{8} = 3
\end{eqnarray}\] What is the variance? Verify both the mean and variance by simulation.
Tip
Consider an unfair coin with a \(p\) probability of heads (\(x=1\)) and a \(1-p\) probability of tails (\(x=0\)), where \(p\) is a parameter between \(0\) and \(1\). The theoretical mean is \[\begin{eqnarray}
\mathbb{E}[X_{i}] = 1[p] + 0[1-p] = p
\end{eqnarray}\] and the theoretical variance is \[\begin{eqnarray}
\mathbb{V}[X_{i}]
= [1 - p]^2 p + [0 - p]^2 [1-p] = [1 - p]^2 p + p^2 [1-p]
= [1-p]p\left( [1-p] + p\right) = [1-p] p.
\end{eqnarray}\] So the theoretical standard deviation is \(\mathbb{s}[X_{i}]=\sqrt{[1-p] p}\).
Tip
Suppose \(X_{i}\) is a discrete random variable with this probability mass function: \[\begin{eqnarray}
X_{i} &=& \begin{cases}
-1 & \text{ with probability } \frac{1}{2 \lambda^2} \\
0 & \text{ with probability } 1-\frac{1}{\lambda^2} \\
+1 & \text{ with probability } \frac{1}{2\lambda^2}
\end{cases},
\end{eqnarray}\] where \(\lambda>0\) is a parameter. What is the theoretical standard deviation?
Tip
For a discrete uniform random variable with th sample space \(\{1,2,3,4,5\}\), calculate the theoretical median and IQR.
Weighted Data.
Sometimes, you may have a dataset of values and probability weights. Othertimes, you can calculate them yourself. In either case, you can explicitly do the computations for discrete data. Given data on unique outcome \(x\) and their frequency \(\hat{p}_{x}=\sum_{i=1}^{n}\mathbf{1}\left(X_{i}=x\right)/n\), we compute \[\begin{eqnarray}
\hat{M} &=& \sum_{x} x \hat{p}_{x}.
\end{eqnarray}\]
Note
Suppose we flipped a coin \(100\) times and found that \(76\) were heads and \(23\) were tails. The estimated probabilities are \(76/100\) for the outcome \(X_{1}=1\) and \(24/100\) for the outcome \(X_{i}=0\). We compute the mean as \(\hat{M}=1\times 0.76 + 0 \times 0.24 = 0.76\).
Code
# Compute a sample estimate using probability weightsP <-table(X) #table of countsp <-c(P)/length(X) #frequencies (must sum to 1)x <-as.numeric(names(p)) #unique valuescbind(x,p)## x p## 0 0 0.246## 1 1 0.754# Sample Mean EstimateX_mean <-sum(x*p)X_mean## [1] 0.754
Tip
Try estimating the sample mean the two different ways for another random sample
Code
x <-c(0,1,2)x_probs <-c(1/3,1/3,1/3)X <-sample(x, prob=x_probs, 1000, replace=T)# First Way (Computerized)mean(X)## [1] 1.032# Second Way (Explicit Calculations)# start with a table of counts like the previous example
This idea generalizes the mean to a weighted mean: an average where different values contribute to the final result with varying levels of importance. For each outcome \(x\) we have a weight \(W_{x}\) and compute \[\begin{eqnarray}
\hat{M} &=& \frac{\sum_{x} x W_{x}}{\sum_{x} W_{x}} = \sum_{x} x w_{x},
\end{eqnarray}\] where \(w_{x}=\frac{W_{x}}{\sum_{x'} W_{x'}}\) is normalized version of \(W_{x}\) that implies \(\sum_{x}w_{x}=1\).1
Many continuous random variables are parameterized by their means and variances. For example, the exponential distribution has parameter \(\lambda\), which corresponds to the theoretical mean \(1/\lambda\) and variance \(1/\lambda^2\). For another example, the two parameters of the normal distribution are \(\mu\) and \(\sigma\), which corresponds to the theoretical mean and variance.
Code
# Exponential Random VariableX <-rexp(5000, 2)m <-mean(X)round(m, 2)## [1] 0.5# Normal Random VariableX <-rnorm(5000, 1, 2)round(mean(X), 2)## [1] 0.94round(var(X), 2)## [1] 4.01
Advanced and Optional
If the sample space is continuous, we can compute the theoretical mean (or expected value) as \[\begin{eqnarray}
\mathbb{E}[X] = \int x f(x) d x,
\end{eqnarray}\] where \(f(x)\) is the probability the random variable takes the particular value \(x\). Similarly, we can compute the theoretical variance as \[\begin{eqnarray}
\mathbb{V}[X_{i}]= \int \left(x - \mathbb{E}[X_{i}] \right)^2 f(x) d x,
\end{eqnarray}\]
For example, consider a random variable with a continuous uniform distribution over \([-1, 1]\). In this case, \(f(x)=1/[1 - (-1)]=1/2\) for each \(x \in [-1, 1]\) and \[\begin{eqnarray}
\mathbb{E}[X_{i}] = \int_{-1}^{1} \frac{x}{2} d x = \int_{-1}^{0} \frac{x}{2} d x + \int_{0}^{1} \frac{x}{2} d x = 0
\end{eqnarray}\] and \[\begin{eqnarray}
\mathbb{V}[X_{i}]= \int_{-1}^{1} x^2 \frac{1}{2} d x = \frac{1}{2} \frac{x^3}{3}|_{-1}^{1} = \frac{1}{6}[1 - (-1)] = 2/6 =1/3
\end{eqnarray}\]
Note that if there are \(K\) unique outcomes and \(W_{x}=1\) then \(\sum_{x}W_{x}=K\) and \(w_{x}=1/K\). This means \(\hat{M} = \sum_{x} x w_{x} = \sum_{x} x /K\), which is just a simple mean.↩︎