A hypothesis test turns a question about the population into a decision: given the data, do we have enough evidence to reject a specific value for the parameter? This chapter conducts those tests two ways (by inverting a confidence interval and by imposing the null), then summarizes the evidence with a \(p\)-value and a \(t\)-value. We also cover one-sided versions and common pitfalls so that “statistically significant” stays linked to its statistical meaning.
Testing Methods
In this chapter, we test hypotheses using data-driven methods that assume much less about the data generating process. There are two main ways to conduct a hypothesis test: inverting a confidence interval and imposing the null. The first treats the distribution of estimates directly; the second explicitly enforces the null hypothesis to evaluate how unusual the observed statistic is. Both approaches rely on the bootstrap to approximate sampling variability.
Before either test can run, we have to name the claim being tested and the alternative we would accept if the data spoke against it.
The null hypothesis \(H_{0}\) is the specific claim about the parameter that we will test.
The alternative hypothesis \(H_{A}\) is the competing claim.
A two-sided hypothesis test covers deviations from the null in either direction (alternative values are higher or lower than the null).
This setup is useful because it forces a single direction of inference: the data either contradict \(H_{0}\) enough to reject it, or they do not, but in no case do they “prove” \(H_{A}\). The most common test concerns the mean, \(H_{0}: \mu = \mu_{0}\), where \(\mu_{0}\) is a hypothesized value, and the alternative values are \(\mu \neq \mu_{0}\). E.g., you hypothesize your stock-retruns have earnings \(\mu_{0}=0\) and consider that the returns could truly be either positive or negative.
Invert a CI.
One way to test a hypothesis is to look at whether a confidence interval contains the hypothesized value: if the value lies outside the interval, sampling variability alone cannot easily explain the gap.
The rejection region is the set of values for the test statistic (or hypothesized parameter) that lead us to reject \(H_{0}\). For a two-sided test at level \(\alpha=0.05\), the rejection region is the two tails outside the central \(95\%\) of the null distribution.
The rejection region is useful as a decision rule that mirrors how we read a confidence interval:
- reject \(H_{0}\) if the hypothesized value falls outside the interval (it is in the rejection region)
- fail to reject \(H_{0}\) if it falls inside
A \(95\%\) confidence interval corresponds to a \(5\%\) rejection region split between the two tails, which links the test level directly to the coverage of the interval (see the previous Confidence Intervals chapter for how the interval is computed).
For example, suppose you hypothesize the mean is \(9\). You then construct a bootstrap distribution with \(95\%\) confidence interval, and find your hypothesized value falls outside of the confidence interval. Then, after accounting for sampling variability (which you estimate), it still seems extremely unlikely that the theoretical mean actually equals \(9\), so you reject that hypothesis. (If the theoretical value landed in the interval, you would “fail to reject” the theoretical mean equals \(9\).)
Code
sample_dat <- USArrests[, 'Murder']
sample_mean <- mean(sample_dat)
# Bootstrap Distribution
n <- length(sample_dat)
set.seed(1) # to be replicable
bootstrap_means <- rep(NA, 999)
for(b in seq_along(bootstrap_means)){
dat_id <- seq_along(sample_dat)
boot_id <- sample(dat_id, replace=TRUE)
dat_b <- sample_dat[boot_id] # c.f. jackknife
mean_b <- mean(dat_b)
bootstrap_means[b] <- mean_b
}
hist(bootstrap_means, breaks=25,
border=NA,
freq=FALSE,
main=NA,
xlab='Bootstrap Samples')
# CI
ci_95 <- quantile(bootstrap_means, probs=c(.025, .975))
abline(v=ci_95, lwd=2)
# H0: mean=9
abline(v=9, col=rgb(1, 0, 0, .8), lwd=2)
The above procedure also generalizes to many other statistics. Perhaps the most informative are those for spread or shape. E.g., you can conduct hypothesis tests for sd and IQR, or skew and kurtosis.
Code
# Bootstrap Distribution for SD
sd_obs <- sd(sample_dat)
bootstrap_sd <- rep(NA, 999)
for(b in seq_along(bootstrap_sd)){
x_b <- sample(sample_dat, replace=TRUE)
sd_b <- sd(x_b)
bootstrap_sd[b] <- sd_b
}
# Test for SD Differences (Invert CI)
sd_null <- 3.6
hist(bootstrap_sd, freq=FALSE,
border=NA, xlab='Bootstrap',
main=NA)
title('Standard Deviations (Invert CI)', font.main=1)
sd_ci <- quantile(bootstrap_sd, probs=c(0.025, .975) )
abline(v=sd_ci, lwd=2)
abline(v=sd_null, lwd=2, col=rgb(1, 0, 0, .8))
To better your understanding, try redoing the above for any function (such as IQR(x_b)/median(x_b))
Suppose you scored \(83\%\) on your exam with \(50\) questions, but think you are really a \(90\%\) student. Explain how you might test your hypothesis to your professor who insists your claim be supported by evidence. What would be the issue if we could not reject your hypothesis? Provide a computer simulation illustrating the issue.
Impose the Null.
We can also compute a null distribution: the sampling distribution of the statistic under the null hypothesis (assuming your null hypothesis was true). We use the bootstrap to loop through a large number of “resamples”. In each iteration of the loop, we impose the null hypothesis and re-estimate the statistic of interest. We then calculate the range of the statistic across all resamples and compare how extreme the original value we observed is.
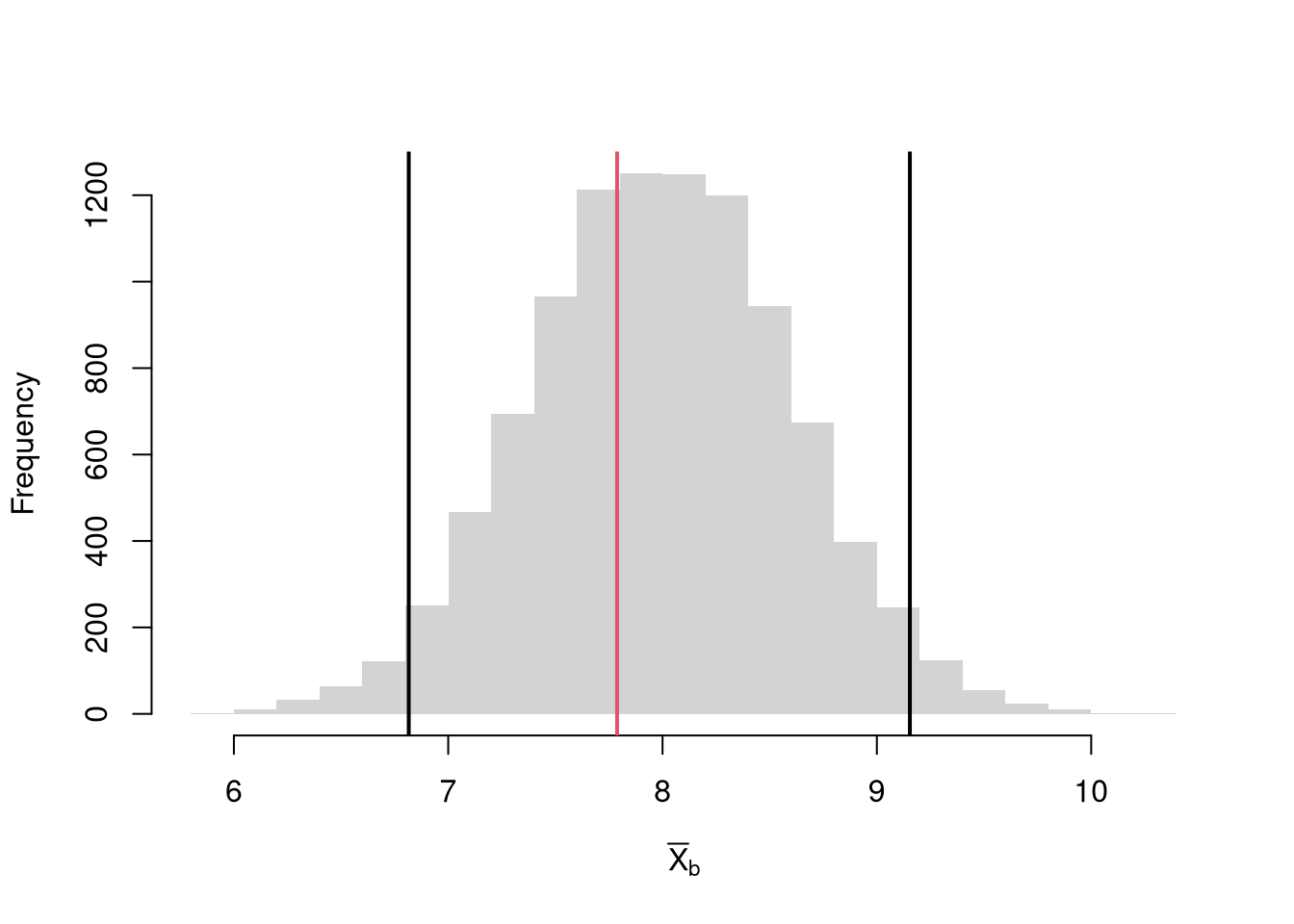
For example, suppose you hypothesize the mean is \(9\). You then construct a \(95\%\) confidence interval around the null bootstrap distribution (resamples centered around \(9\)). If your sample mean falls outside of that interval, then even after accounting for sampling variability (which you estimate), it seems extremely unlikely that the theoretical mean actually equals \(9\), so you reject that hypothesis. (If the sample mean landed in the interval, you would “fail to reject” the theoretical mean equals \(9\).)
Code
sample_dat <- USArrests[, 'Murder']
sample_mean <- mean(sample_dat)
# Bootstrap NULL: mean=9
# Bootstrap shift: center each bootstrap resample so that the distribution satisfies the null hypothesis on average.
set.seed(1)
mu <- 9
bootstrap_means_null <- rep(NA, 999)
for(b in seq_along(bootstrap_means_null)){
dat_b <- sample(sample_dat, replace=TRUE)
mean_b <- mean(dat_b) + (mu - sample_mean) # impose the null via Bootstrap shift
bootstrap_means_null[b] <- mean_b
}
hist(bootstrap_means_null, breaks=25, border=NA, freq=FALSE,
main=NA,
xlab='Null Bootstrap Samples')
ci_95 <- quantile(bootstrap_means_null, probs=c(.025, .975)) # critical region
abline(v=ci_95, lwd=2)
abline(v=sample_mean, lwd=2, col=rgb(0, 0, 1, .8))
Why does adding \((\mu - \hat{M})\) impose the null? A bootstrap resample of the data has a mean that varies around the sample mean \(\hat{M}\), not around the hypothesized \(\mu\). Adding the constant \((\mu - \hat{M})\) slides the whole resampling distribution over so it is centered at \(\mu\) instead. A shift moves the center but leaves the spread and shape unchanged, so the result is a sampling distribution with the null mean and the same variability as the data.
The Normal approximation from the previous chapter can also impose the null: center the interval at the hypothesized value \(\mu\) and use \(\mu \pm q(\alpha/2) \cdot SE(M)\), where \(SE(M)\) is estimated via bootstrap or classical formulas. (While we could also use a Null Jackknife distribution, that is rarely done in practice.) Altogether, there are two different types of confidence intervals that “impose the null”. Until you know more, a conservative rule-of-thumb is to take the larger estimate.
Types of Confidence Interval Estimates that “impose the null”
| Bootstrap (Percentile) |
randomly resample \(n\) observations with replacement and shift |
| Normal |
assume sampling distribution is Normal and use formula \(\pm q(\alpha/2) \cdot SE\) |
\(p\)-values
Reading a hypothesis test off a confidence interval is binary (reject or not); often we also want a number that describes how extreme the observed statistic is relative to the null.
The \(p\)-value is the probability, under the null hypothesis, of seeing a statistic at least as extreme as the one observed. Small \(p\)-values give evidence against the null; the threshold \(p \leq 0.05\) is a convention, not a law of nature. The \(p\)-value is not the probability that the null is true.
The \(p\)-value is useful as a continuous summary of how strongly the data oppose the null, whereas a confidence interval gives only a yes/no answer at a fixed coverage level. For the running mean example, we want the probability that the random variable \(M\) is at least as extreme (far from the null mean of \(9\)) as our observed sample mean \(\hat{M}\).
Recall that we used the bootstrap to estimate the distribution of the sample statistic like the mean, and the null-bootstrap shifted the bootstrap to be centered at a hypothesized value. The bootstrap idea here is to approximate \(M-\mu\), the difference between the sample mean \(M\) and the unknown theoretical mean \(\mu\), with the null-bootstrap analogue \(M^{\text{boot}}_{0}-\mu\), where \(M^{\text{boot}}_{0}=M^{\text{boot}}+(\mu-\hat{M})\) is the recentered bootstrap mean. \[\begin{eqnarray}
& & Prob( |M - \mu| \geq |\hat{M} - \mu| \mid \mu = 9 ) \\
& & \approx Prob( |M^{\text{boot}}_{0}- \mu| \geq |\hat{M}- \mu| \mid \mu = 9) \\
& & = 1-\hat{F}^{|\text{boot}|}_{0}(|\hat{M}-9|),
\end{eqnarray}\] where \(\hat{F}^{|\text{boot}|}_{0}\) is the ECDF of \(|M^{\text{boot}}_{0}- \mu|\).
(Repeating the null bootstrap from above for reference.)
Code
sample_dat <- USArrests[, 'Murder']
sample_mean <- mean(sample_dat)
set.seed(1)
# Bootstrap NULL: mean=9
# Bootstrap shift: center each bootstrap resample so that the distribution satisfies the null hypothesis on average.
mu <- 9
bootstrap_means_null <- rep(NA, 999)
for(b in seq_along(bootstrap_means_null)){
dat_b <- sample(sample_dat, replace=TRUE)
mean_b <- mean(dat_b) + (mu - sample_mean) # impose the null via Bootstrap shift
bootstrap_means_null[b] <- mean_b
}
hist(bootstrap_means_null, breaks=25, border=NA, freq=FALSE,
main=NA,
xlab='Null Bootstrap Samples')
ci_95 <- quantile(bootstrap_means_null, probs=c(.025, .975)) # critical region
abline(v=ci_95, lwd=2)
abline(v=sample_mean, lwd=2, col=rgb(0, 0, 1, .8))
Code
# Two-Sided Test, ALTERNATIVE: mean < 9 or mean >9
# Visualize Two Sided Prob. & reject region boundary
par(mfrow=c(1, 2))
hist(bootstrap_means_null-mu,
freq=FALSE, breaks=20,
border=NA,
main=NA,
xlab=expression('Null Bootstrap for M - '~mu))
abline(v=sample_mean-mu, col=rgb(0, 0, 1, .8))
ci_95 <- quantile(bootstrap_means_null-mu, probs=c(0.025, .975))
abline(v=ci_95, lwd=2)
# Equivalent Visualization
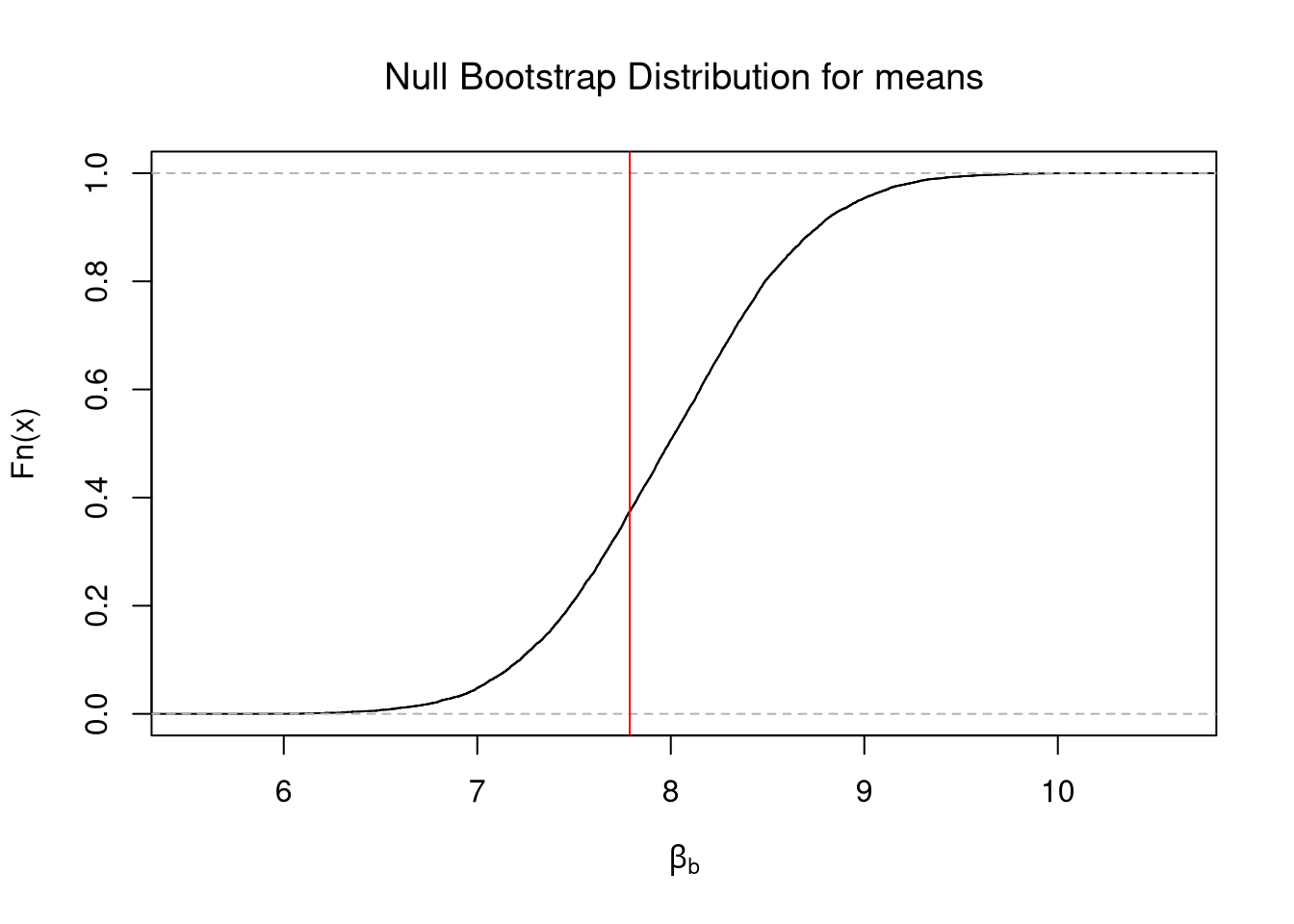
boot_absval <- abs(bootstrap_means_null-mu)
Fhat_abs0 <- ecdf(boot_absval)
plot(Fhat_abs0,
main=NA,
xlab=expression('Null Bootstrap for |M - '~mu~'|'))
abline(v=abs(sample_mean-mu), col=rgb(0, 0, 1, .8))
# with Two Sided Probability
p2 <- 1 - Fhat_abs0( abs(sample_mean-mu) )
title( paste0('p=', round(p2, 3)), font.main=1)
You can conduct hypothesis test using \(p\)-values instead of confidence intervals. It is common to use this decision rule:
- reject the null at the \(5\%\) level if \(p \leq 0.05\)
- fail to reject the null at the \(5\%\) level if \(p > 0.05\)
Caveats.
Beware that a common misreading of the \(p\)-value as “the probability the null is true”. That is false. A \(p\)-value is the frequency you see something at least as extreme as your statistic under the null hypothesis.
Often, one may also see or hear “\(p<.05\): statistically significant” and “\(p>.05\): not statistically significant”. That is decision making on purely statistical grounds, and it may or may not be suitable for your context. You simply need to know that whoever says those things is using \(5\%\) as a critical value to reject a null hypothesis.
Running many hypothesis tests inflates the chance of a false rejection. At the \(5\%\) level, you expect roughly \(1\) in \(20\) true nulls to be rejected by chance alone, so if you test \(20\) independent nulls and find \(1\) “significant” result, that result is what you would expect even when every null is true. The fix is to correct the level (e.g., Bonferroni: use \(0.05/k\) when running \(k\) tests) or to pre-specify a small set of hypotheses before looking at the data.
Code
# Purely-Statistical Decision Making
# via Two Sided Test
if(p2 >.05){
print('fail to reject the null that mean=9, at the 5% level')
} else {
print('reject the null that mean=9 in favor of either <9 or >9, at the 5% level')
}
## [1] "reject the null that mean=9 in favor of either <9 or >9, at the 5% level"
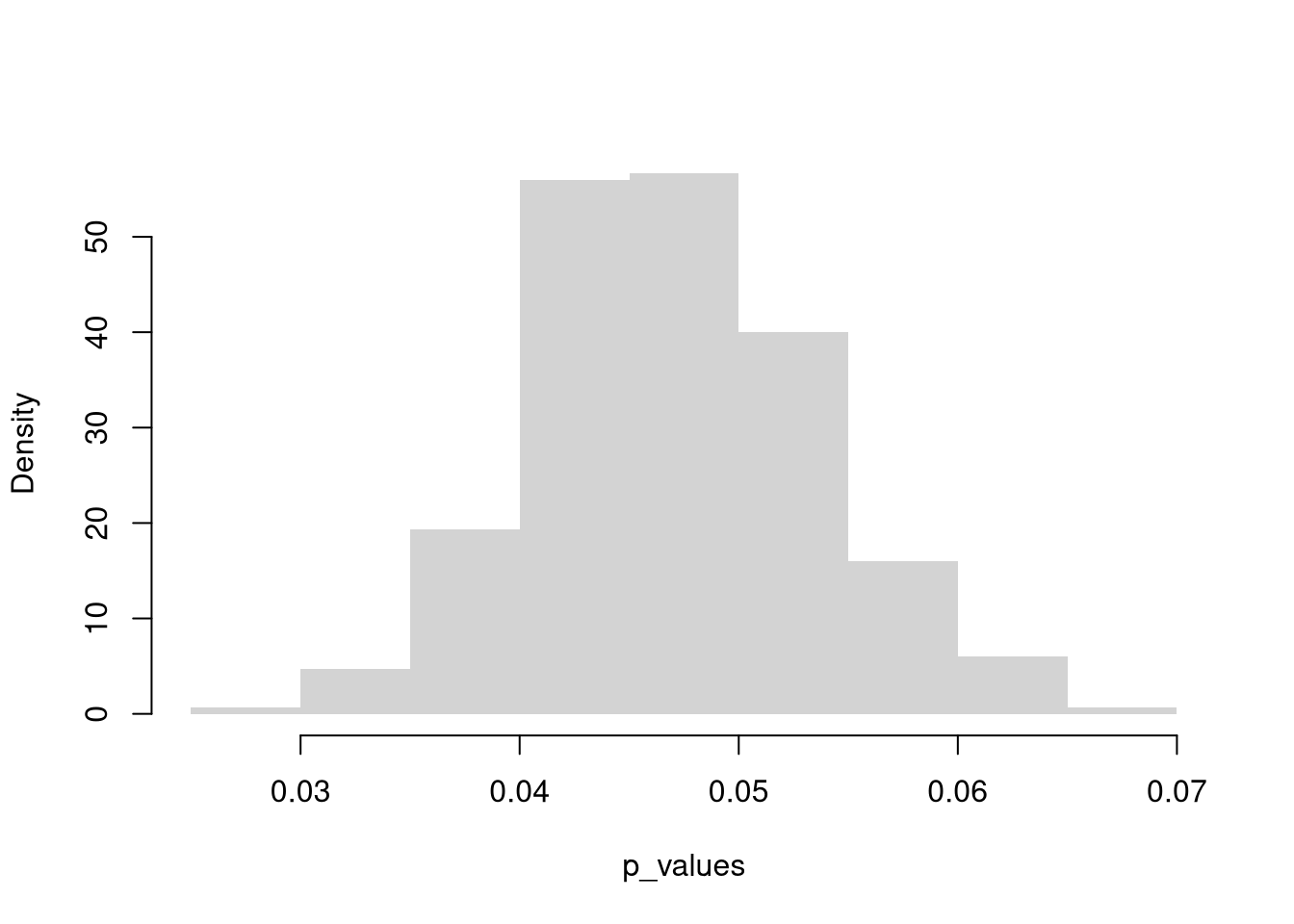
Also note that the \(p\)-value is itself a function of data, and hence a random variable that changes from sample to sample. Given that the \(5\%\) level is somewhat arbitrary, and that the \(p\)-value both varies from sample to sample and is often misunderstood, it makes sense to give specific \(p\)-values a limited role in decision making.
Code
p_values <- rep(NA, 300)
for(b2 in seq(p_values)){
bootstrap_means_null_p <- rep(NA, 999)
for(b in seq_along(bootstrap_means_null_p)){
dat_b <- sample(sample_dat, replace=TRUE)
mean_b <- mean(dat_b) + (mu - sample_mean) # impose the null
bootstrap_means_null_p[b] <- mean_b
}
Fhat_abs0 <- ecdf( abs(bootstrap_means_null_p-mu) )
p2 <- 1- Fhat_abs0( abs(sample_mean-mu) )
p_values[b2] <- p2
}
hist(p_values, freq=FALSE,
border=NA, main=NA)
Other Statistics
\(t\)-values.
Different studies have different \(SE(M)\), so the raw difference \(\hat{M} - \mu\) is hard to compare across studies; we need to express the deviation in standard-error units.
The \(t\)-value (or \(t\)-statistic) standardizes the deviation of \(\hat{M}\) from the hypothesized \(\mu\) by the standard error, \[t = \frac{M - \mu}{SE(M)}.\] Using a standardized statistic makes results comparable across studies and connects to a well-studied reference distribution (Normal in large samples, Student’s \(t\) in small).
The \(t\)-value is useful as a portable test statistic: a \(t\) of \(2.05\) has roughly the same evidentiary weight whether the underlying data are measured in dollars, hours, or grams, because the units cancel between numerator and denominator. For any specific sample we must approximate the standard error. Using the theory-driven approach, we compute \(\hat{t}=(\hat{M}-\mu)/(\hat{S}/\sqrt{n})\). Using the data-driven approach, we compute \(\hat{t}=(\hat{M}-\mu)/(\hat{SE}^{\text{jack}})\) or \(\hat{t}=(\hat{M}-\mu)/(\hat{SE}^{\text{boot}})\). In any case, we can use bootstrapping to estimate the variability of the \(t\) statistic, just like we did with the mean.
Code
#null hypothesis
mu <- 9
# t statistic
jackknife_means <- rep(NA, length(sample_dat))
for(i in seq_along(jackknife_means)){
dat_i <- sample_dat[-i]
jackknife_means[i] <- mean(dat_i)
}
jackknife_se <- sd(jackknife_means)*sqrt(length(sample_dat))
sample_t <- (sample_mean - mu)/jackknife_se
# Boostrap Null Distribution
bootstrap_t_null <- rep(NA, 999)
for(b in seq_along(bootstrap_t_null)){
dat_b <- sample(sample_dat, replace=TRUE)
mean_b <- mean(dat_b) + (mu - sample_mean) # impose the null by recentering
# Compute t stat using jackknife ses (same as above)
jackknife_means_b <- rep(NA, length(dat_b))
for(i in seq_along(jackknife_means_b)){
jackknife_means_b[i] <- mean(dat_b[-i])
}
jackknife_se_b <- sd(jackknife_means_b)*sqrt(length(dat_b))
jackknife_t_b <- (mean_b - mu)/jackknife_se_b
bootstrap_t_null[b] <- jackknife_t_b
}
# Plot the null distribution and CI
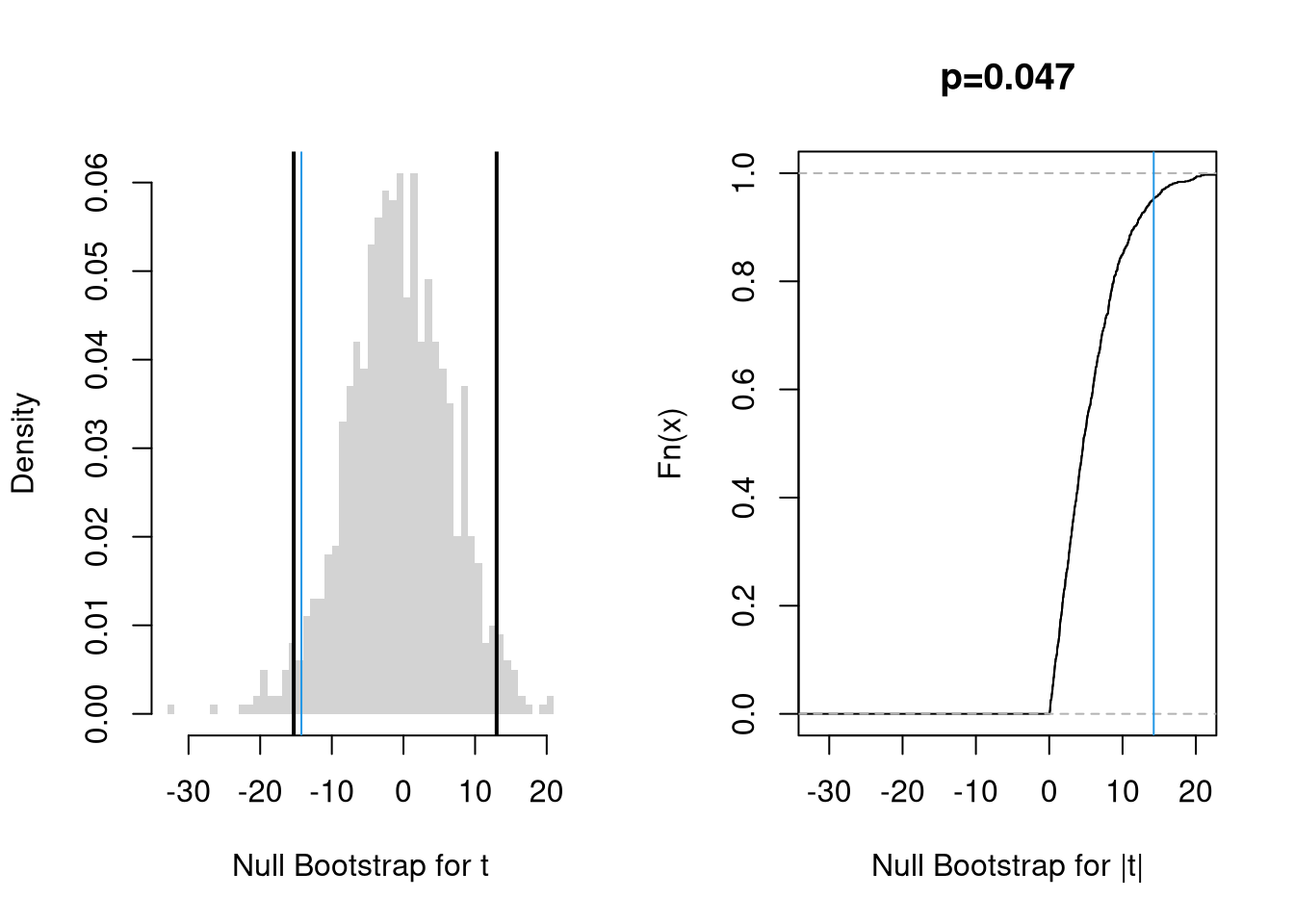
par(mfrow=c(1, 2))
hist(bootstrap_t_null, border=NA, breaks=50,
freq=FALSE, main=NA, xlab='Null Bootstrap for t')
abline(v=sample_t, col=rgb(0, 0, 1, .8))
ci_95 <- quantile(bootstrap_t_null, probs=c(0.025, 0.975) )
abline(v=ci_95, lwd=2)
# Compute the p-value for two-sided test
Fhat0 <- ecdf(abs(bootstrap_t_null))
plot(Fhat0,
xlim=range(bootstrap_t_null, sample_t),
xlab='Null Bootstrap for |t|',
main=NA)
abline(v=abs(sample_t), col=rgb(0, 0, 1, .8))
p <- 1 - Fhat0( abs(sample_t) )
title( paste0('p=', round(p, 3)), font.main=1)
Code
if(p >.05){
print('fail to reject the null that mean=9, at the 5% level')
} else {
print('reject the null that mean=9 in favor of either <9 or >9, at the 5% level')
}
## [1] "fail to reject the null that mean=9, at the 5% level"
There are several benefits to this statistic:
- uses the same statistic for different hypothesis tests
- makes the statistic comparable across different studies
- removes dependence on unknown parameters by normalizing with a standard error
- makes the null distribution theoretically known asymptotically (approximately)
The last point implies we are typically dealing with a normal distribution that is well-studied, or another well-studied distribution derived from it. We will discuss this more when comparing means.
Quantiles and Shape Statistics.
Bootstrap allows hypothesis tests for any statistic, not just the mean, without relying on parametric theory. For example, the above procedures generalize from means to quantile statistics like medians.
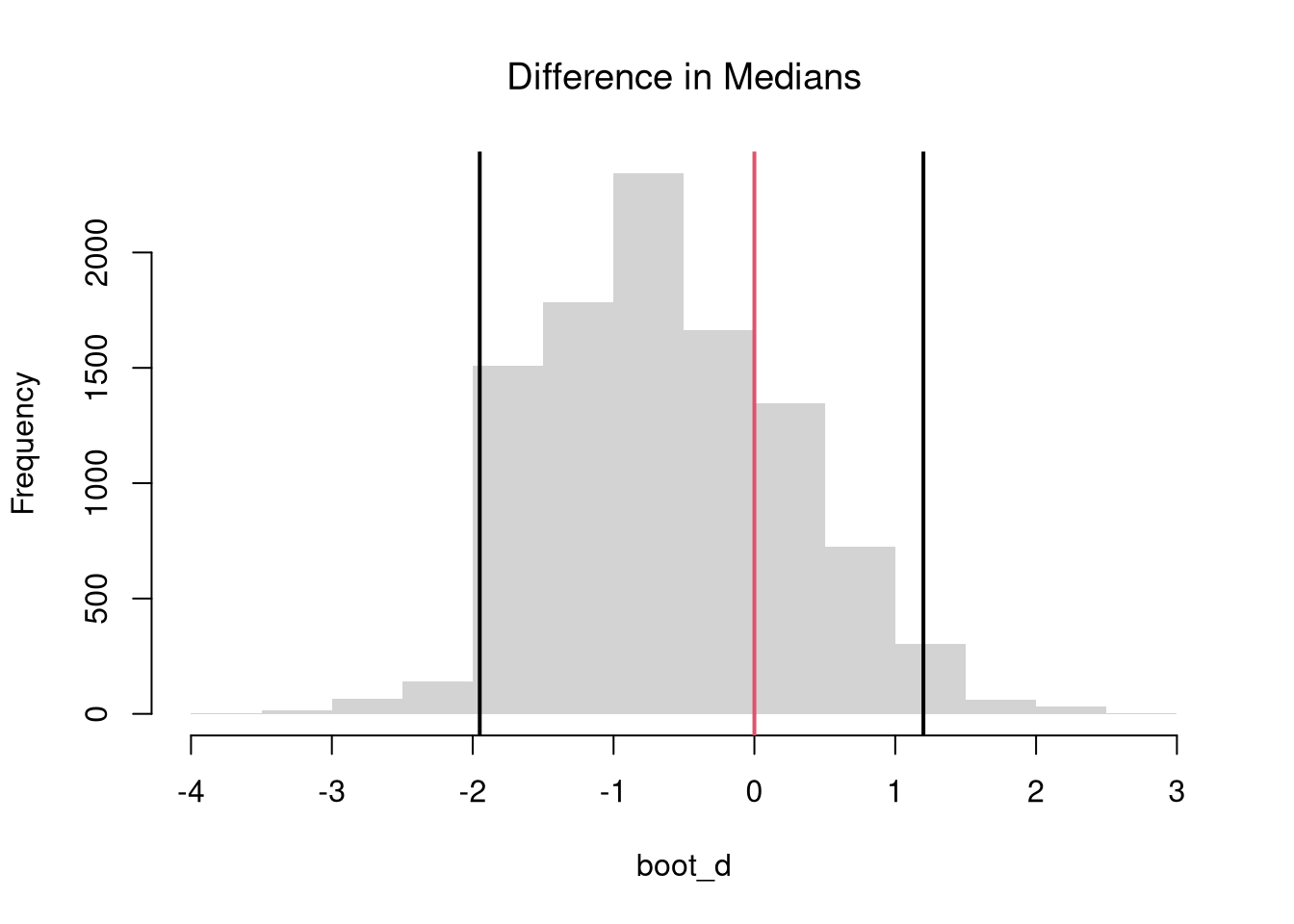
Code
# Test for Median Differences (Impose the Null)
# Bootstrap Null Distribution for the median
# Each Bootstrap shifts medians so that median = q_null
q_obs <- quantile(sample_dat, probs=.5)
q_null <- 7.8
bootstrap_quantile_null <- rep(NA, 999)
for(b in seq_along(bootstrap_quantile_null)){
x_b <- sample(sample_dat, replace=TRUE) #bootstrap sample
q_b <- quantile(x_b, probs=.5) # median
q_b_null <- q_b + (q_null - q_obs) # impose the null
bootstrap_quantile_null[b] <- q_b_null
}
# 2-Sided Test for Medians
hist(bootstrap_quantile_null-q_null,
border=NA, freq=FALSE, xlab='Null Bootstrap',
main=NA)
title('Medians (Impose Null)', font.main=1)
median_ci <- quantile(bootstrap_quantile_null-q_null, probs=c(.025, .975))
abline(v=median_ci, lwd=2)
abline(v=q_obs-q_null, lwd=2, col=rgb(0, 0, 1, .8))
Code
# 2-Sided Test for Median Difference
## Null: No Median Difference
1 - ecdf( abs(bootstrap_quantile_null-q_null))( abs(q_obs-q_null) )
## [1] 0.5695696
Conduct a hypothesis test for whether the upper quartile is statistically different from \(12\).
Code
q_obs <- quantile(sample_dat, probs=.75)
One-Sided Tests
Above, we tested whether the observed statistic is either extremely high or low. This is known as a two-sided test. There are also two one-sided tests (left tail: observed statistic is extremely low, right tail: observed statistic is extremely high). For a concrete example, consider whether the mean statistic, \(M\), is centered on a theoretical value of \(\mu=9\) for the population. If your null hypothesis is that the theoretical mean is nine, \(H_{0}: \mu =9\), and you calculated the mean for your sample as \(\hat{M}\), then you can consider any one of these three alternative hypotheses:
- \(H_{A}: \mu \neq 9\), a two-tail test
- \(H_{A}: \mu < 9\), a left-tail test
- \(H_{A}: \mu > 9\), a right-tail test
A fitness tracker manufacturer claims that users take more than \(8{,}000\) steps per day on average. A sample of \(25\) users has \(\hat{M}=8{,}492\) steps and \(\hat{S}=1{,}200\) steps. Test at the \(5\%\) level using theory-based intervals.
(a) Hypotheses. The claim is a right-tail alternative: \(H_{0}: \mu = 8000\) versus \(H_{A}: \mu > 8000\).
(b) Test statistic. The classical standard error is \(\hat{S}/\sqrt{n} = 1200/\sqrt{25} = 240\), so \(t = (8492 - 8000)/240 \approx 2.05\).
(c) Decision. The right-tail critical value at \(5\%\) is \(q_{0.95} \approx 1.645\) from the Normal. Since \(t = 2.05 > 1.645\), we reject \(H_{0}\).
(d) Conclusion. At the \(5\%\) level, the data are consistent with the manufacturer’s claim: there is evidence the population mean exceeds \(8{,}000\) steps per day.
Code
M_hat <- 8492
S_hat <- 1200
n <- 25
mu0 <- 8000
SE <- S_hat / sqrt(n)
t_stat <- (M_hat - mu0) / SE
t_stat
## [1] 2.05
# Right-tail p-value from the standard Normal approximation
1 - pnorm(t_stat)
## [1] 0.02018222
One-sided hypothesis tests can be conducted by inverting a one-sided confidence interval (covered in the previous chapter) or by computing a one-sided \(p\)-value.
One-Sided \(p\)-values.
The \(p\)-value for a one-sided test is more straightforward to implement via a bootstrap null distribution.
For a left-tail test, we examine \[\begin{eqnarray}
p = Prob( M < \hat{M} \mid \mu = 9 )
&\approx& Prob( M^{\text{boot}} < \hat{M} \mid \mu = 9 ) = \hat{F}^{\text{boot}}_{0}(\hat{M}),
\end{eqnarray}\] where \(\hat{F}^{\text{boot}}_{0}\) is the ECDF of the bootstrap null distribution. We reject the null if \(p < 0.05\) at the \(5\%\) level, and otherwise fail to reject.
For a right-tail test, we examine \(p=Prob( M > \hat{M} \mid \mu = 9 ) \approx 1-\hat{F}^{\text{boot}}_{0}(\hat{M})\).
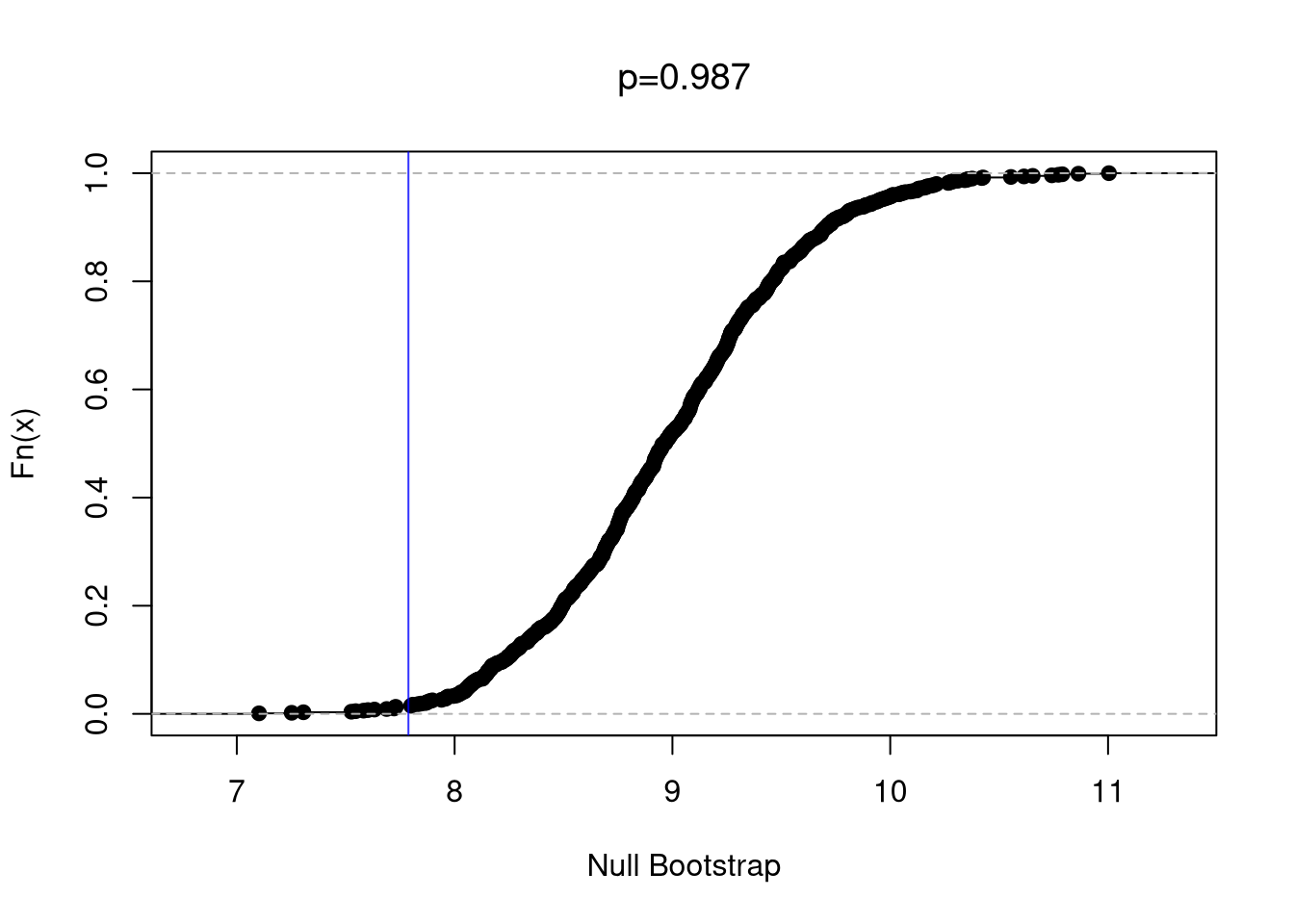
Code
# Right-tail Test, ALTERNATIVE: mean > 9
# Equivalent Visualization with p-value
Fhat0 <- ecdf(bootstrap_means_null) # Look at right tail
plot(Fhat0,
main=NA,
xlab='Null Bootstrap')
abline(v=sample_mean, col=rgb(0, 0, 1, .8))
p1 <- 1- Fhat0(sample_mean) #Compute right tail prob: 0.987
title( paste0('p=', round(p1, 3)), font.main=1)
Code
if(p1 >.05){
print('fail to reject the null that mean=9, at the 5% level')
} else {
print('reject the null that mean=9 in favor of >9, at the 5% level')
}
## [1] "fail to reject the null that mean=9, at the 5% level"
The left-tail test uses the other side of the same null distribution.
Code
# Left-tail Test, ALTERNATIVE: mean < 9
# Compute left-tail prob: p = F(sample_mean)
p_left <- Fhat0(sample_mean)
p_left
## [1] 0.01301301
if(p_left >.05){
print('fail to reject the null that mean=9, at the 5% level')
} else {
print('reject the null that mean=9 in favor of <9, at the 5% level')
}
## [1] "reject the null that mean=9 in favor of <9, at the 5% level"
Notice that the recentering adjustment affects two-sided tests (because they depend on distance from the null mean) but not one-sided tests (because adding a constant does not change rank order). Specifically, \(p = Prob( M < \hat{M} \mid \mu = 9 ) = Prob( M - \mu < \hat{M} - \mu \mid \mu = 9 )\). That is intuitively also why the \(t\)-value can be used for both one and two-sided hypothesis tests.
Code
# See that the 'recentering' matters for two-sided tests
ecdf( abs(bootstrap_means_null-mu) )( abs(sample_mean-mu) )
## [1] 0.966967
ecdf( abs(bootstrap_means_null) )( abs(sample_mean) )
## [1] 0.01301301
# See that the 'recentering' doesn't matter for one-sided ones
ecdf( bootstrap_means_null-mu)( sample_mean-mu)
## [1] 0.01301301
ecdf( bootstrap_means_null )( sample_mean)
## [1] 0.01301301
Exercises
Comment the script you wrote for this chapter, then restart R and check that it runs from a clean session, then check the script with AI as explained in Working with AI. Write three sentences from memory on the main statistical idea of this chapter, and ask the assistant what is wrong, vague, or missing. Finish with your own questions about whatever you found hardest.
Explain the difference between “rejecting the null hypothesis” and “proving the alternative hypothesis is true.” Why is the phrase “fail to reject” used instead of “accept the null”?
Suppose you collect a sample of \(n = 50\) observations with \(\hat{M} = 22.4\) and \(\hat{S} = 6.0\). You want to test \(H_{0}: \mu = 20\) against \(H_{A}: \mu \neq 20\) at the \(5\%\) level. Compute the \(t\)-value using theory-driven standard errors and determine whether you reject or fail to reject.
Using the USArrests dataset in R, test the hypothesis that the population mean of Assault equals \(150\) by constructing a bootstrap null distribution. Compute the two-sided \(p\)-value and state whether you reject or fail to reject at the \(5\%\) level.
Recall
This chapter built hypothesis tests two ways (invert a CI and impose the null), introduced the \(p\)-value and the \(t\)-value, and flagged the multiple-comparisons pitfall. The fitness-tracker example tied these ideas together: with \(\hat{M}=8492\), \(\hat{S}=1200\), and \(n=25\), the standard error is \(SE = 1200/\sqrt{25} = 240\) and the \(t\)-value for \(H_{0}: \mu = 8000\) is \((8492 - 8000)/240 \approx 2.05\), which exceeds the right-tail critical value \(1.645\) at the \(5\%\) level and so rejects the null. In the next chapter we round out the probability toolbox with the Binomial, Poisson, and Beta distributions, plus Bayes’ theorem and the Law of Total Probability.