EQ3 <- sapply(1:(2*N), function(n){
# Market Mechanisms
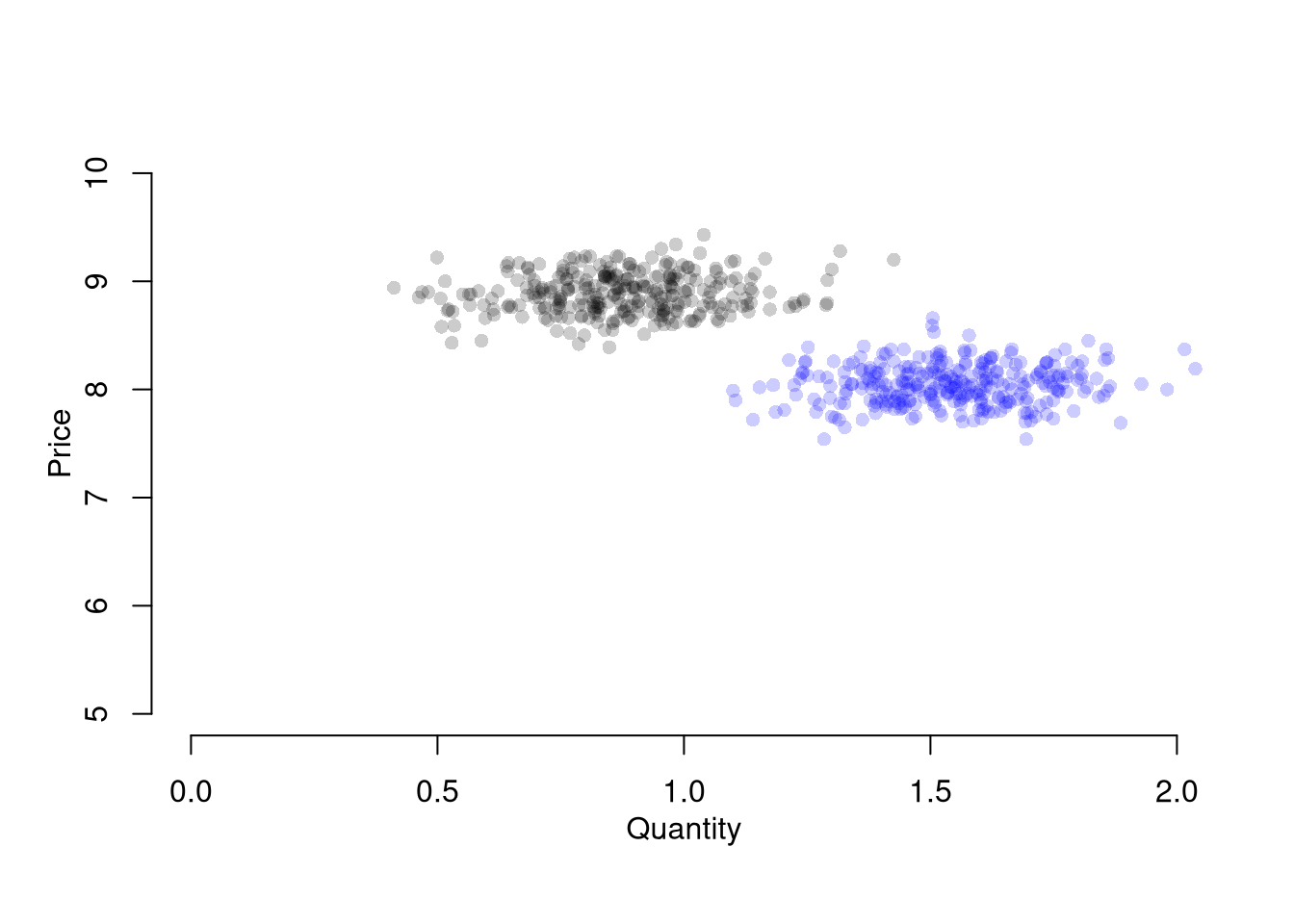
demand <- qd_fun(P)
supply <- qs_fun(P)
# Compute EQ (what we observe)
eq_id <- which.min( abs(demand-supply) )
eq <- c(P=P[eq_id], Q=demand[eq_id])
# Return Equilibrium Observations
return(eq)
})
dat3 <- data.frame(t(EQ3), cost='1', T=1:ncol(EQ3))
dat3_pre <- dat3[dat3$T <= N ,]
dat3_post <- dat3[dat3$T > N ,]
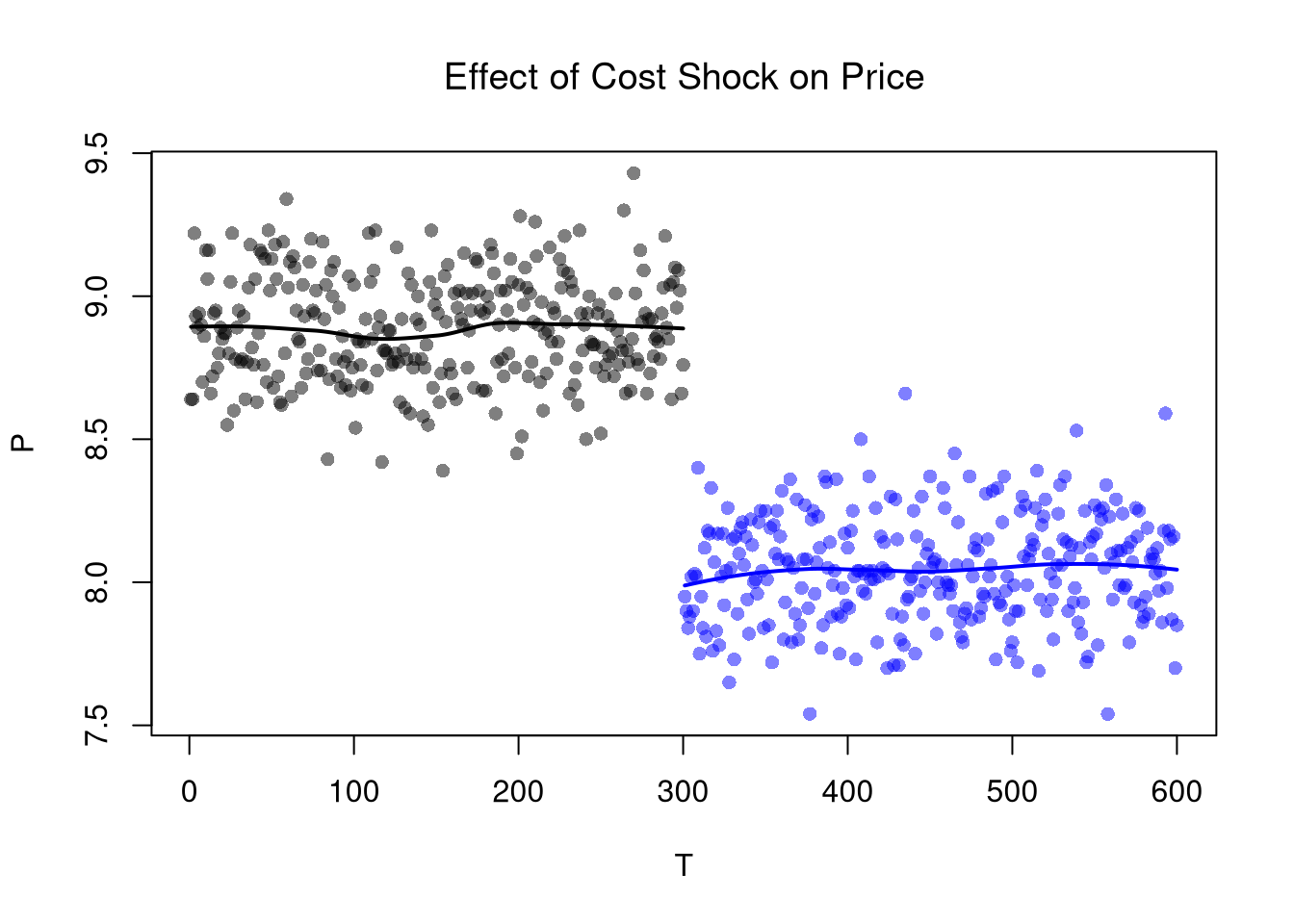
# Plot Price Data
par(mfrow=c(1,2))
plot(P~T, dat2, main='Effect of Cost Shock on Price',
font.main=1, pch=16, col=cols, cex=.5)
lines(x1, predict(regP1), col=rgb(0,0,0), lwd=2)
lines(x2, predict(regP2), col=rgb(0,0,1), lwd=2)
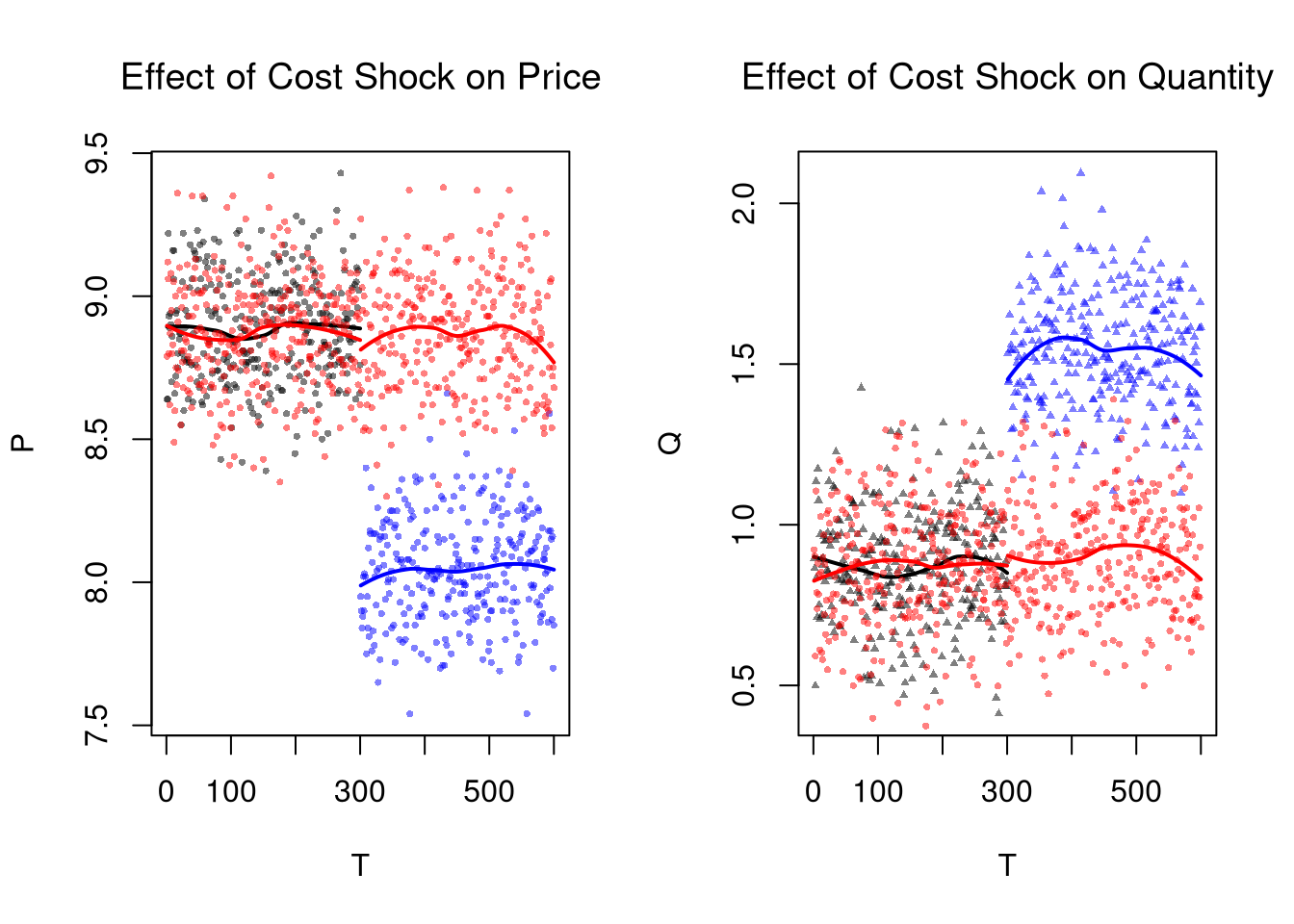
# W/ Control group
points(P~T, dat3, pch=16, col=rgb(1,0,0,.5), cex=.5)
regP3a <- loess(P~T, dat3_pre)
x3a <- regP3a$x
lines(x3a, predict(regP3a), col=rgb(1,0,0), lwd=2)
regP3b <- loess(P~T, dat3_post)
x3b <- regP3b$x
lines(x3b, predict(regP3b), col=rgb(1,0,0), lwd=2)
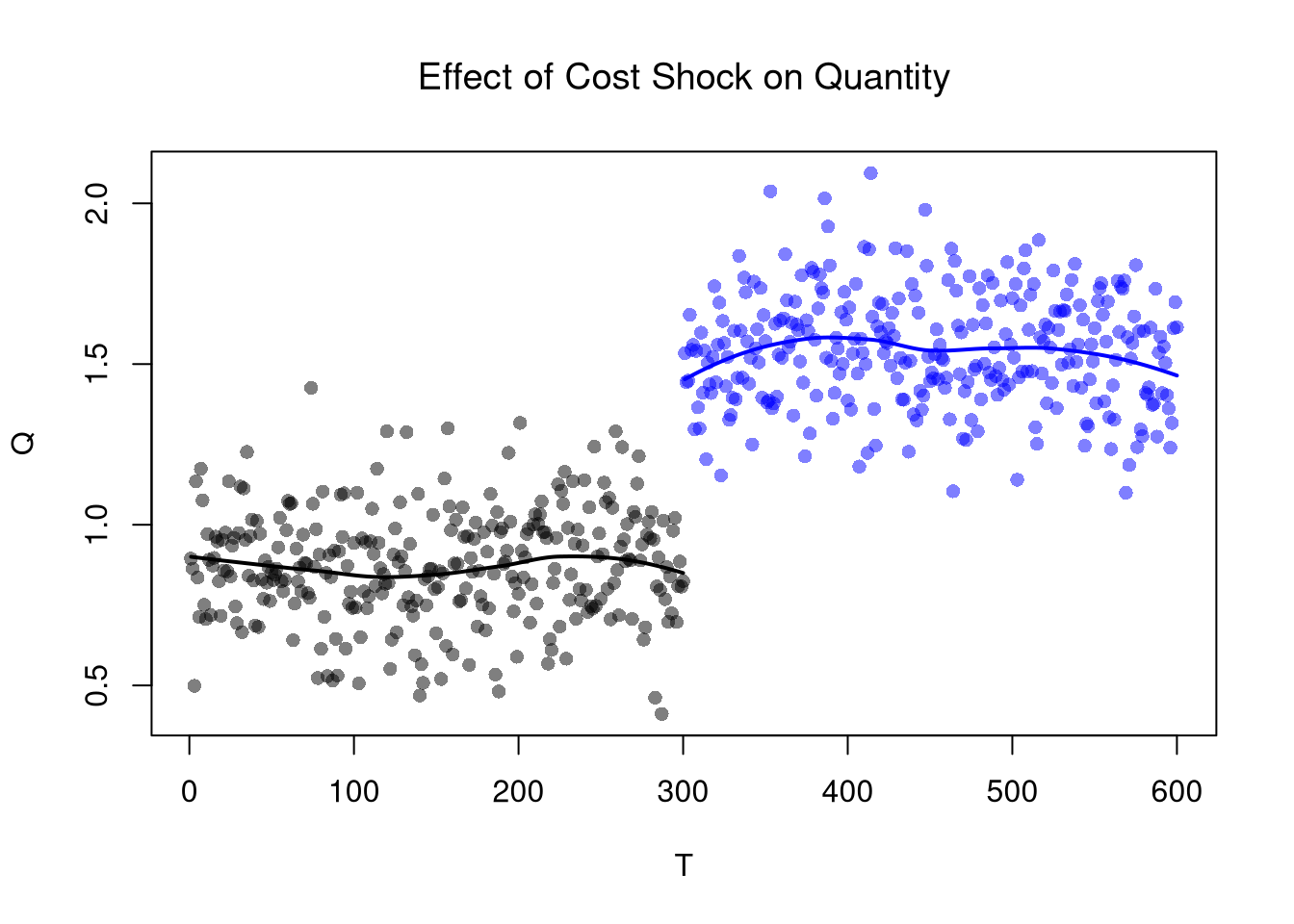
# Plot Quantity Data
plot(Q~T, dat2, main='Effect of Cost Shock on Quantity',
font.main=1, pch=17, col=cols, cex=.5)
lines(x1, predict(regQ1), col=rgb(0,0,0), lwd=2)
lines(x2, predict(regQ2), col=rgb(0,0,1), lwd=2)
# W/ Control group
points(Q~T, dat3, pch=16, col=rgb(1,0,0,.5), cex=.5)
regQ3a <- loess(Q~T, dat3_pre)
lines(x3a, predict(regQ3a), col=rgb(1,0,0), lwd=2)
regQ3b <- loess(Q~T, dat3_post)
lines(x3b, predict(regQ3b), col=rgb(1,0,0), lwd=2)