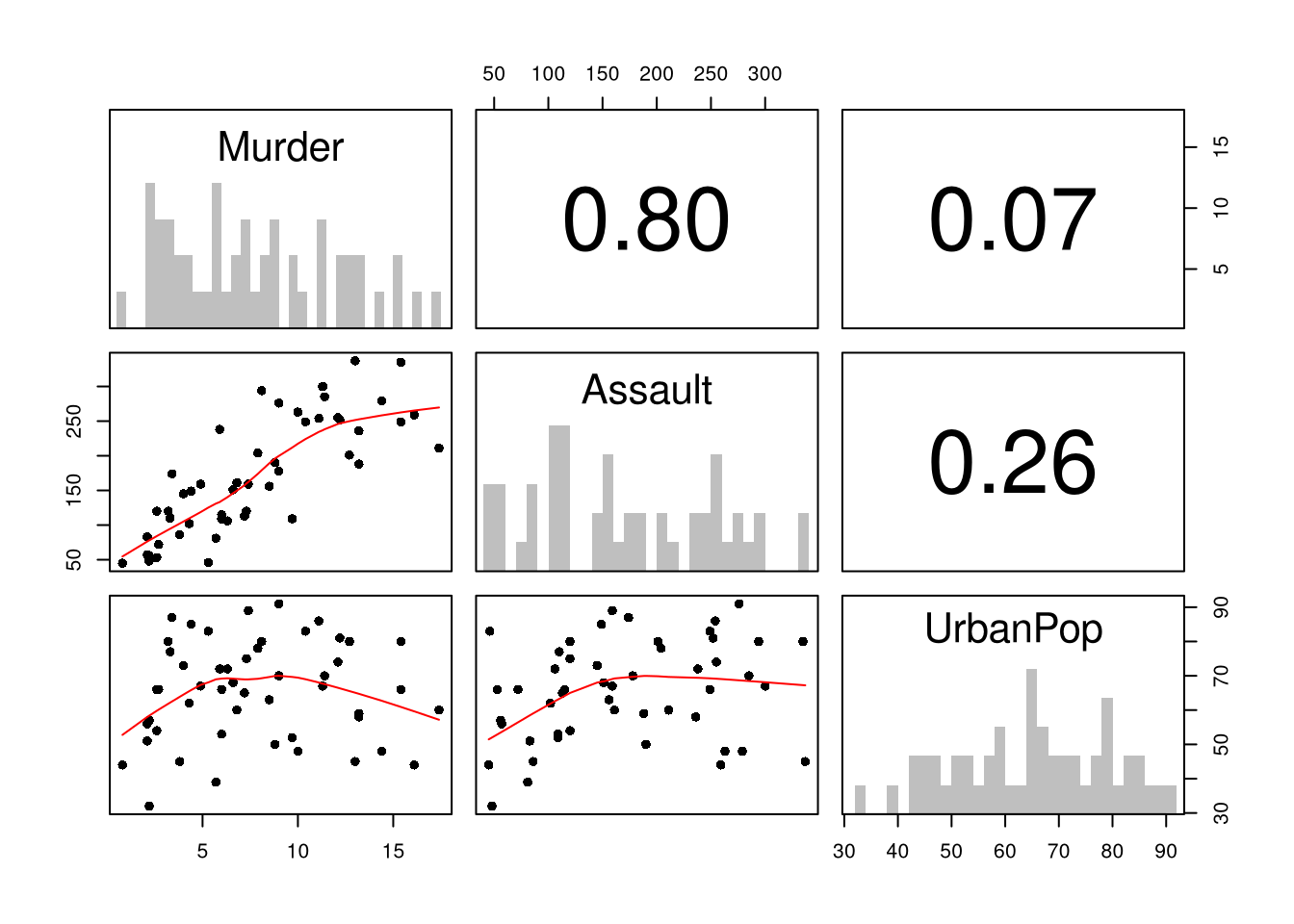
First, you can summarize a dataset with multiple variables using the previous tools. This is often the first indication as to whether you should analyze the data using a linear model. Such figures are almost always a good idea to make first, as they can suggest issues that you were not even thinking about.
Code
# Inspect Dataset on police arrests for the USA in 1973head(USArrests)## Murder Assault UrbanPop Rape## Alabama 13.2 236 58 21.2## Alaska 10.0 263 48 44.5## Arizona 8.1 294 80 31.0## Arkansas 8.8 190 50 19.5## California 9.0 276 91 40.6## Colorado 7.9 204 78 38.7library(psych)pairs.panels( USArrests[,c('Murder','Assault','UrbanPop')],hist.col=grey(0,.25), breaks=30, density=F, hist.border=NA, # Diagonalellipses=F, rug=F, smoother=F, pch=16, col='red'# Lower Triangle )
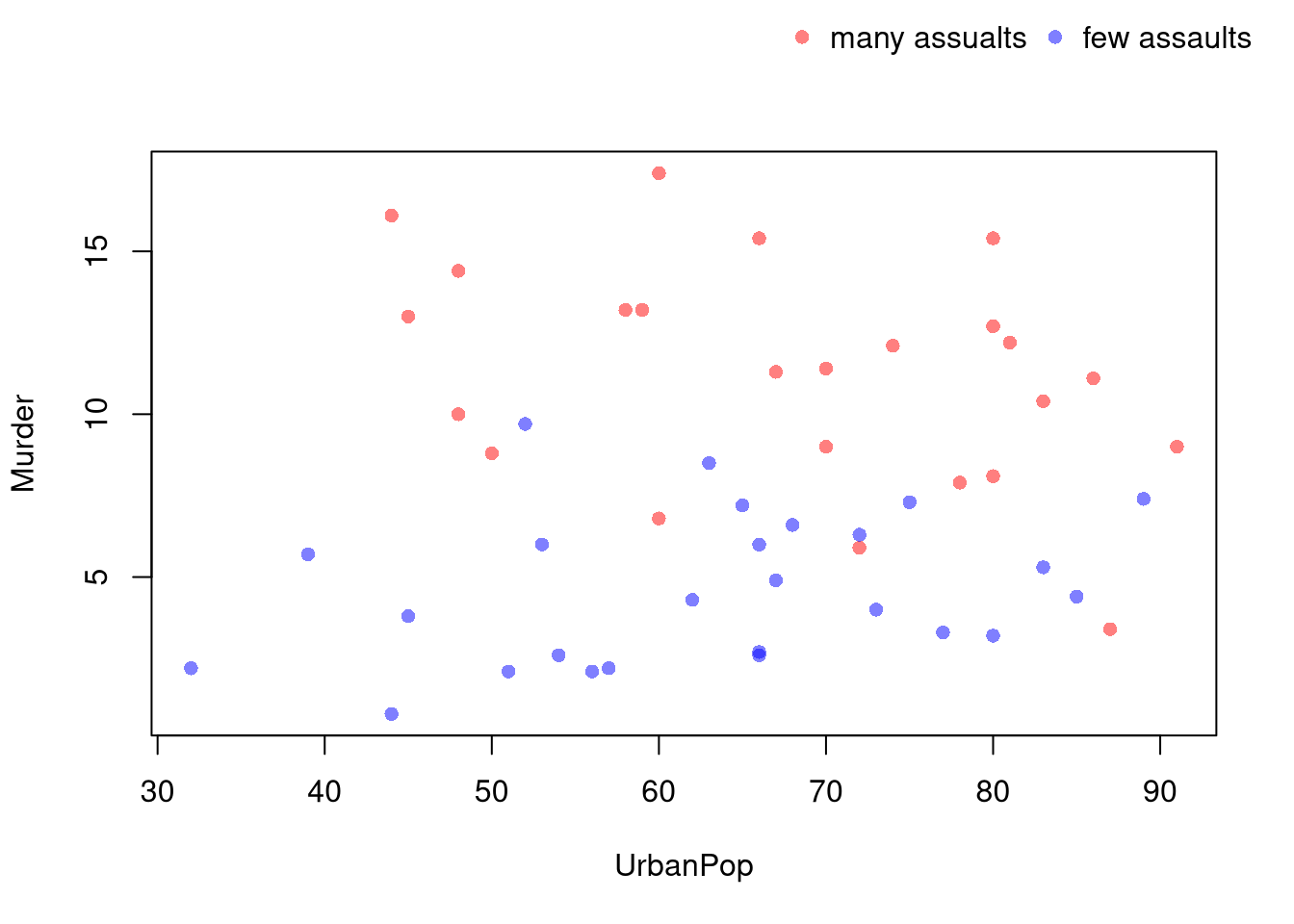
You can also use size, color, and shape to distinguish conditional relationships.
Code
# High Assault Areasassault_high <- USArrests$Assault >median(USArrests$Assault)col_high <-rgb(1,0,0,.5)col_low <-rgb(0,0,1,.5)cols <-ifelse(assault_high, col_high, col_low)# Scatterplot# Show High Assault Areas via 'cex=' or 'pch='# Could further add regression lines for each data splitplot(Murder~UrbanPop, USArrests, pch=16, col=cols)outer_legend <-function(...) { opar <-par(fig=c(0, 1, 0, 1), oma=c(0, 0, 0, 0), mar=c(0, 0, 0, 0), new=TRUE)on.exit(par(opar))plot(0, 0, type='n', bty='n', xaxt='n', yaxt='n')legend(...)}outer_legend('topright',legend=c('many assualts', 'few assaults'),pch=16, col=c(col_high, col_low),horiz=T, cex=1, bty='n')
library(plotly)# Scatter PlotUSArrests$ID <-rownames(USArrests)fig <-plot_ly( USArrests, x =~UrbanPop, y =~Assault,mode='markers',type='scatter',hoverinfo='text',text =~paste('<b>', ID, '</b>',"<br>Urban :", UrbanPop,"<br>Assault:", Assault,"<br>Murder :", Murder),color=~Murder,marker=list(size=~Murder,opacity=0.5,showscale=T, colorbar =list(title='Murder Arrests (per 100,000)')))fig <-layout(fig,showlegend=F,title='Crime and Urbanization in America 1975',xaxis =list(title ='Percent of People in an Urban Area'),yaxis =list(title ='Assault Arrests per 100,000 People'))fig
20.2 Model Diagnostics
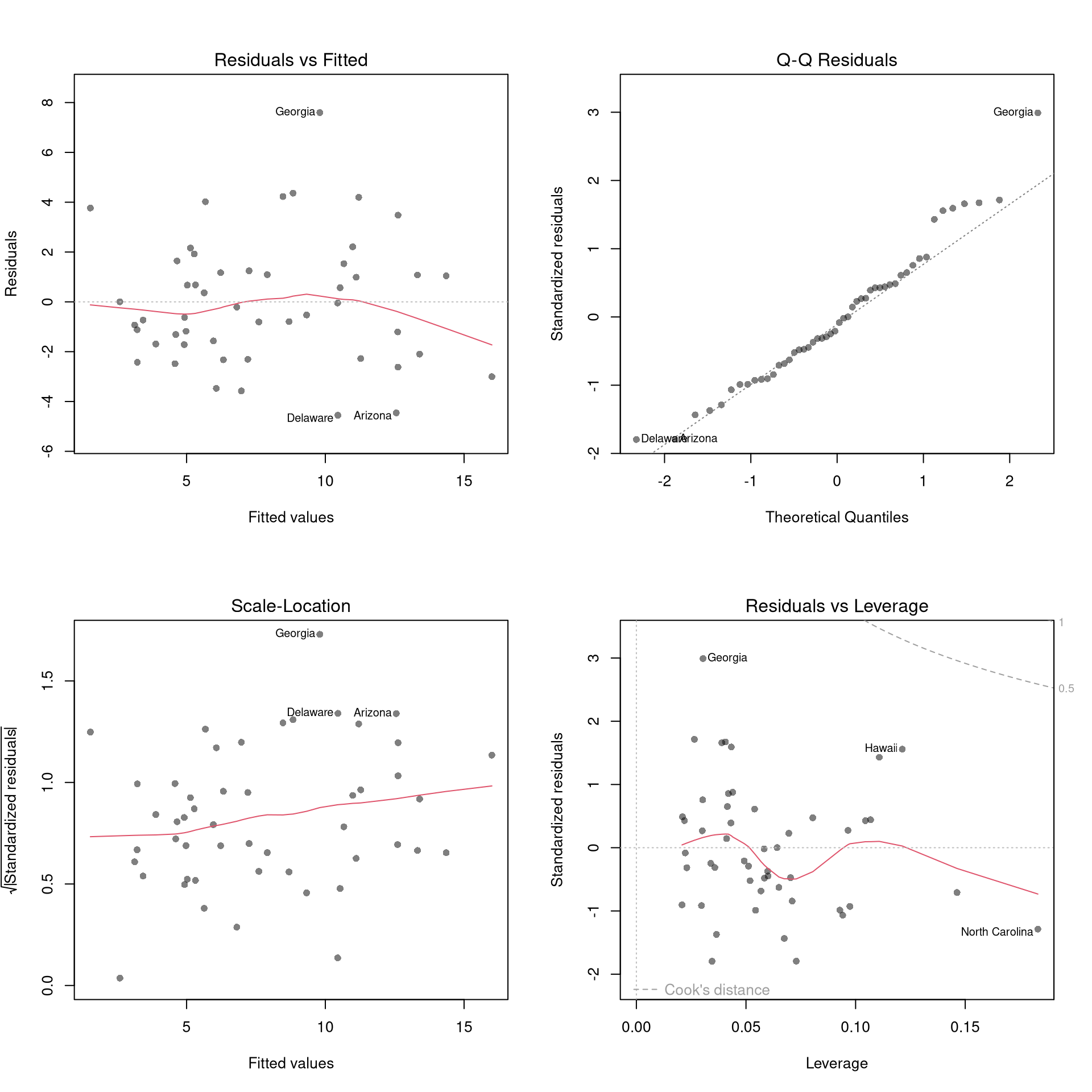
There’s little sense in getting great standard errors for a terrible model. Plotting your regression object a simple and easy step to help diagnose whether your model is in some way bad. We next go through what each of these figures show.
The first diagnostic plot examines outliers in terms the observed outcome \(\hat{Y}_i\) being far from its prediction \(\hat{y}_i\). You may be interested in such outliers because they can (but do not have to) unduly influence your estimates.
The third diagnostic plot examines another type of outlier, the observed explanatory variable \(\hat{X}_{i}\) is far from the others. A point has high leverage if the estimates change dramatically when you estimate the model without that data point.
Standardized residuals are \(r_i=\frac{\hat{e}_i}{s_{[i]}\sqrt{1-h_i}}\), where \(s_{[i]}\) is the root mean squared error of a regression with the \(i\)th observation removed and \(h_i\) is the leverage of residual \(\hat{e}_{i}\).
The fourth plot further assesses outliers in the explanatory variables (\(X\)) using Cook’s Distance, which sums of all prediction changes when observation \(i\) is removed and scales proportionally to the mean square error \[\begin{eqnarray}
D_{i}
&=& \frac{\sum_{j} \left( \hat{y_j} - \hat{y_j}_{[i]} \right)^2 }{ p \hat{S}^2 }
= \frac{\hat{e}_{i}^2}{p \hat{S}^2 } \frac{h_i}{(1-h_i)^2} \\
\hat{S}^2 &=& \frac{\sum_{i} \hat{e}_{i}^2 }{n-K}.
\end{eqnarray}\]
This is when one explanatory variable in a multiple linear regression model can be linearly predicted from the others with a substantial degree of accuracy. Coefficient estimates may change erratically in response to small changes in the model or the data. (In the extreme case, there are more variables than observations \(K>n\) and an infinite number of solutions to a linear model.) To diagnose collinearity, we can use the Variance Inflation Factor: \(\hat{VIF}_{k}=\frac{1}{1-\hat{R}^2_k}\), where \(\hat{R}^2_k\) is the \(\hat{R}^2\) for the regression of \(\hat{X}_k\) on the other covariates \(\hat{X}_{-k}\) (a regression that does not involve the response variable \(\hat{Y}\))
Code
car::vif(reg) sqrt(car::vif(reg)) >2# problem?
Normality.
The second plot examines whether the residuals are normally distributed. Your OLS coefficient estimates do not depend on the normality of the residuals. (Good thing, because there’s no reason the residuals of economic phenomena should be so well behaved.) Many hypothesis tests are, however, affected by the distribution of the residuals. For these reasons, you may be interested in assessing normality
Code
par(mfrow=c(1,2))hist(resid(reg),main='Histogram of Residuals',font.main=1, border=NA)qqnorm(resid(reg),main="Normal Q-Q Plot of Residuals",font.main=1, col=grey(0,.5), pch=16)qqline(resid(reg), col=1, lty=2)#shapiro.test(resid(reg))
Heterskedasticity may also matters for variability estimates. This is not shown in the plot, but you can conduct a simple test
Code
library(lmtest)lmtest::bptest(reg)
20.3 Data Transformations
Transforming variables can often improve your model fit while still estimating it via OLS. This is because OLS only requires the model to be “linear in the parameters”. Under the assumptions of the model is correctly specified, the following table is how we can interpret the coefficients of the transformed data. (Note for small changes, \(\Delta ln(x) \approx \Delta x / x = \Delta x \% \cdot 100\).)
Specification
Regressand
Regressor
Derivative
Interpretation (If True)
linear–linear
\(y\)
\(x\)
\(\Delta y = \beta_1\cdot\Delta x\)
Change \(x\) by one unit \(\rightarrow\) change \(y\) by \(\beta_1\) units.
log–linear
\(ln(y)\)
\(x\)
\(\Delta y \% \cdot 100 \approx \beta_1 \cdot \Delta x\)
Change \(x\) by one unit \(\rightarrow\) change \(y\) by \(100 \cdot \beta_1\) percent.
linear–log
\(y\)
\(ln(x)\)
\(\Delta y \approx \frac{\beta_1}{100}\cdot \Delta x \%\)
Change \(x\) by one percent \(\rightarrow\) change \(y\) by \(\frac{\beta_1}{100}\) units
log–log
\(ln(y)\)
\(ln(x)\)
\(\Delta y \% \approx \beta_1\cdot \Delta x \%\)
Change \(x\) by one percent \(\rightarrow\) change \(y\) by \(\beta_1\) percent
Now recall from micro theory that an additively seperable and linear production function is referred to as ``perfect substitutes’‘. With a linear model and untranformed data, you have implicitly modelled the different regressors \(X\) as perfect substitutes. Further recall that the’‘perfect substitutes’’ model is a special case of the constant elasticity of substitution production function. Here, we will build on http://dx.doi.org/10.2139/ssrn.3917397, and consider box-cox transforming both \(X\) and \(y\). Specifically, apply the box-cox transform of \(y\) using parameter \(\lambda\) and apply another box-cox transform to each \(x\) using the same parameter \(\rho\) so that \[\begin{eqnarray}
Y^{(\lambda)}_{i} &=& \sum_{k=1}^{K}\beta_{k} X^{(\rho)}_{ik} + \epsilon_{i}\\
Y^{(\lambda)}_{i} &=&
\begin{cases}
\lambda^{-1}\left[ (Y_i+1)^{\lambda}- 1\right] & \lambda \neq 0 \\
\log\left(Y_i+1\right) & \lambda=0
\end{cases}.\\
x^{(\rho)}_{i} &=&
\begin{cases}
\rho^{-1}\left[ (X_i)^{\rho}- 1\right] & \rho \neq 0 \\
\log\left(X_{i}+1\right) & \rho=0
\end{cases}.
\end{eqnarray}\]
Notice that this nests:
linear-linear \((\rho=\lambda=1)\).
linear-log \((\rho=1, \lambda=0)\).
log-linear \((\rho=0, \lambda=1)\).
log-log \((\rho=\lambda=0)\).
If \(\rho=\lambda\), we get the CES production function. This nests the ‘’perfect substitutes’’ linear-linear model (\(\rho=\lambda=1\)) , the ‘’cobb-douglas’’ log-log model (\(\rho=\lambda=0\)), and many others. We can define \(\lambda=\rho/\lambda'\) to be clear that this is indeed a CES-type transformation where
\(\rho \in (-\infty,1]\) controls the “substitutability” of explanatory variables. E.g., \(\rho <0\) is ‘’complementary’’.
\(\lambda\) determines ‘’returns to scale’‘. E.g., \(\lambda<1\) is’‘decreasing returns’’.
We compute the mean squared error in the original scale by inverting the predictions; \[\begin{eqnarray}
\hat{y}_{i} =
\begin{cases}
\left[ \hat{y}_{i}^{(\lambda)} \cdot \lambda \right]^{1/\lambda} -1 & \lambda \neq 0 \\
\exp\left( \hat{y}_{i}^{(\lambda)} \right) -1 & \lambda=0
\end{cases}.
\end{eqnarray}\]
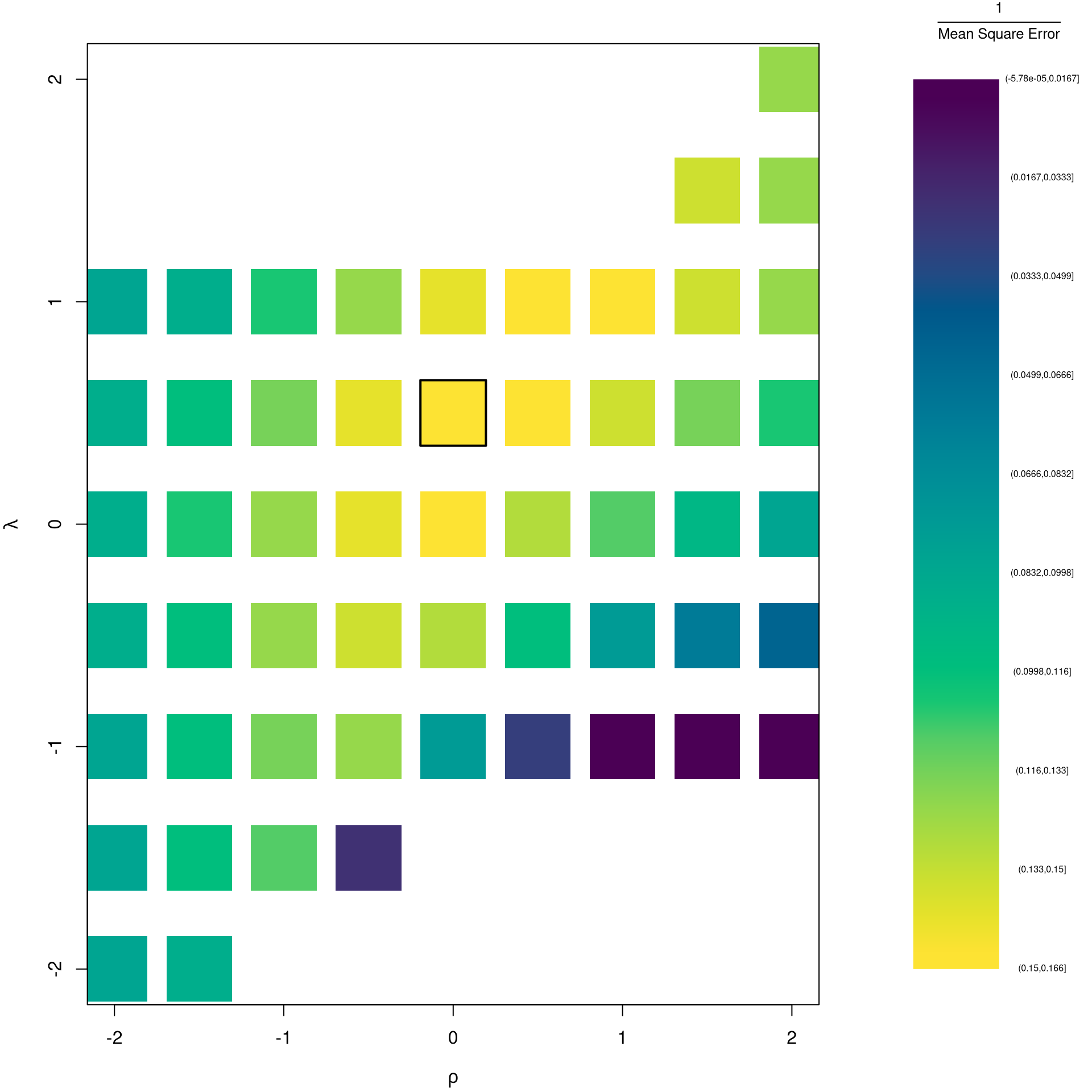
It is easiest to optimize parameters in a 2-step procedure called `concentrated optimization’. We first solve for \(\hat{\beta}(\rho,\lambda)\) and compute the mean squared error \(MSE(\rho,\lambda)\). We then find the \((\rho,\lambda)\) which minimizes \(MSE\).
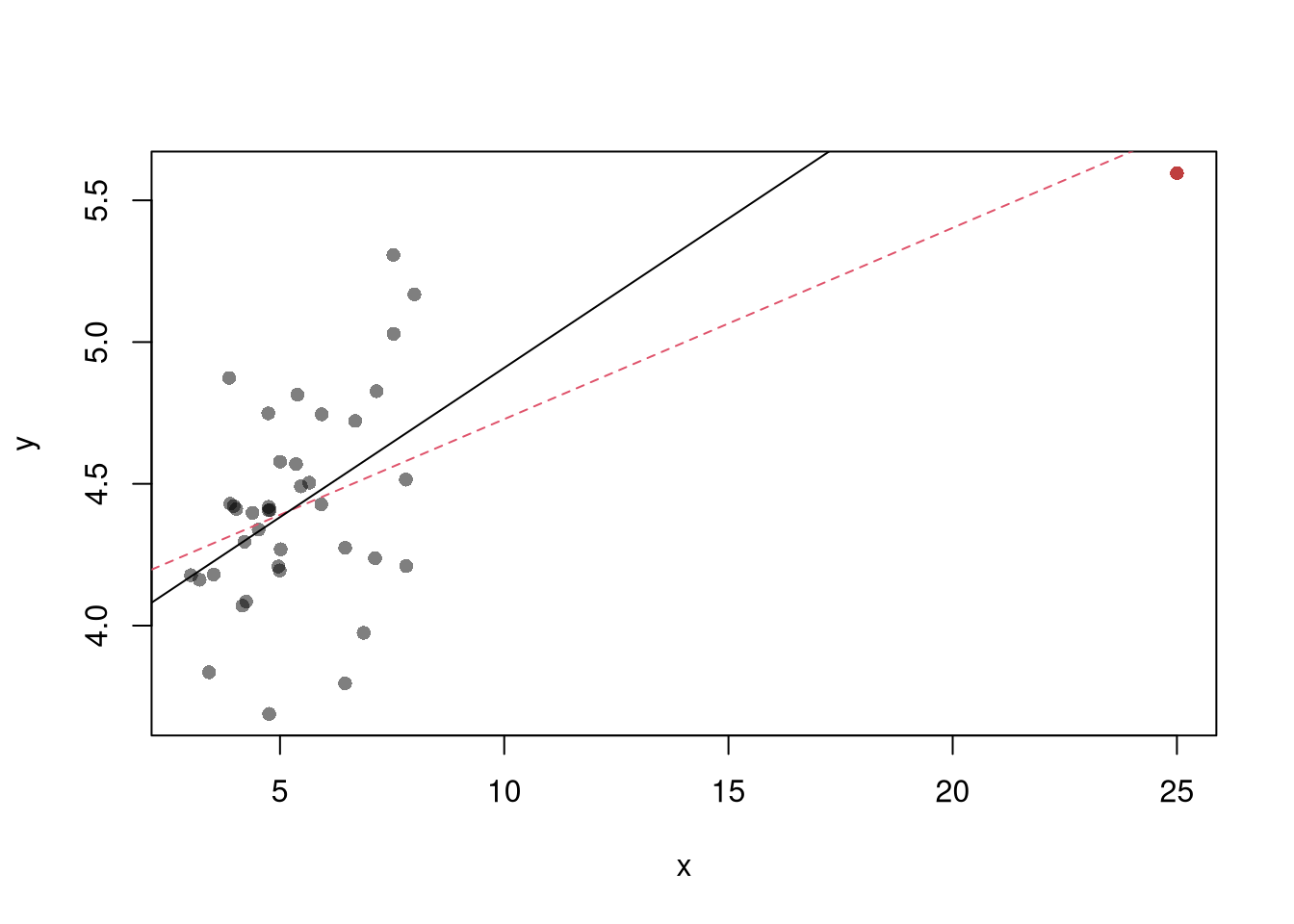
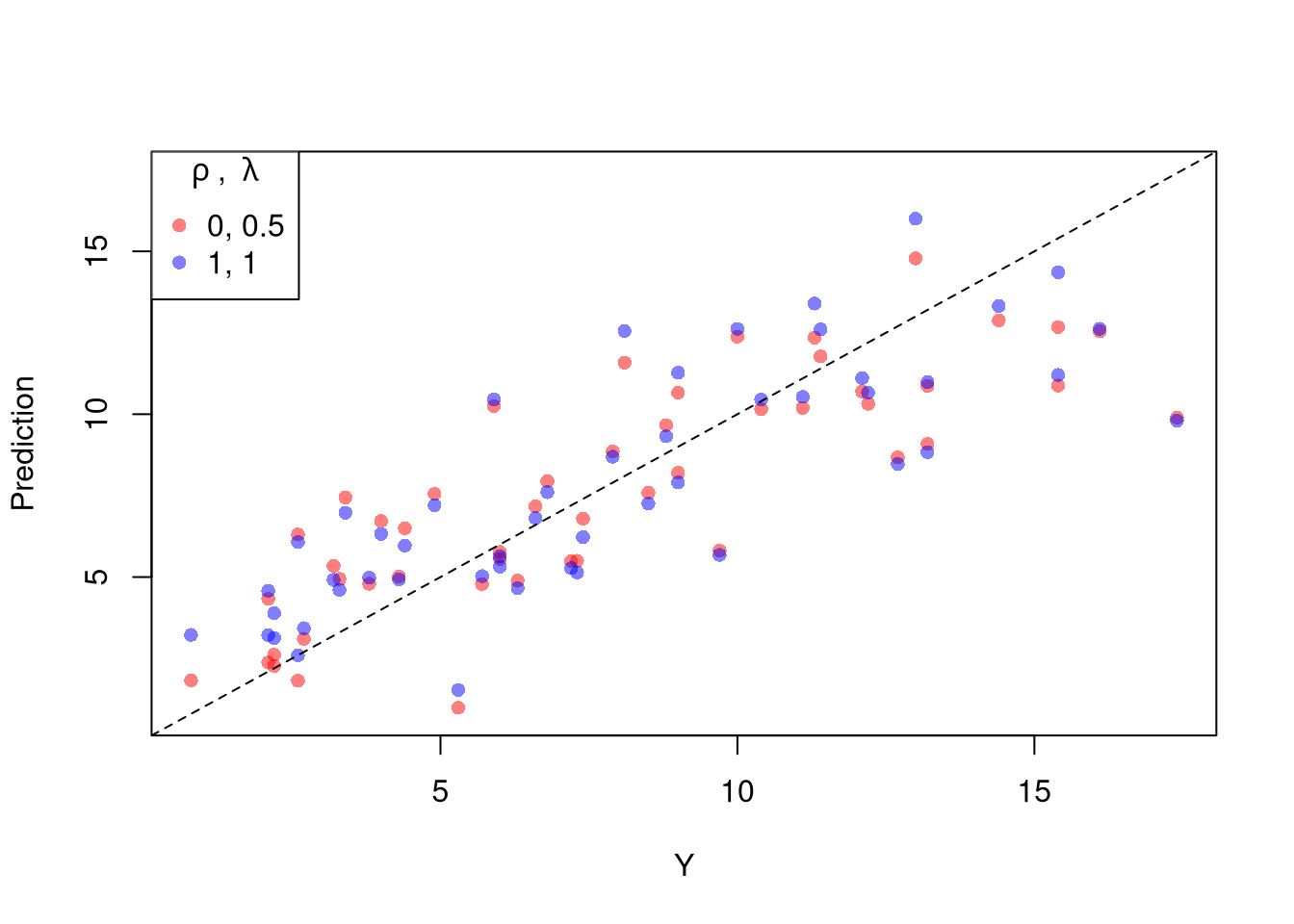
The parameters \(-1,0,1,2\) are easy to interpret and might be selected instead if there is only a small loss in fit. (In the above example, we might choose \(\lambda=0\) instead of the \(\lambda\) which minimized the mean square error). You can also plot the specific predictions to better understand the effect of data transformation beyond mean squared error.
When explicitly transforming data according to \(\lambda\) and \(\rho\), these parameters increase the degrees of freedom by two. The default hypothesis testing procedures do not account for you trying out different transformations, and should be adjusted by the increased degrees of freedom. Specification searches deflate standard errors and are a major source for false discoveries.
Note that if you are ultimately interested in the outcome \(Y\), then transforming/untransforming \(Y\) can introduce a bias. To understand when you might be better off sticking with an untransformed outcome variable, see the literature on “smearing”.
Belsley, D. A., Kuh, E., and Welsch, R. E. (1980). Regression Diagnostics: Identifying influential data and sources of collinearity. Wiley. https://doi.org/10.1002/0471725153