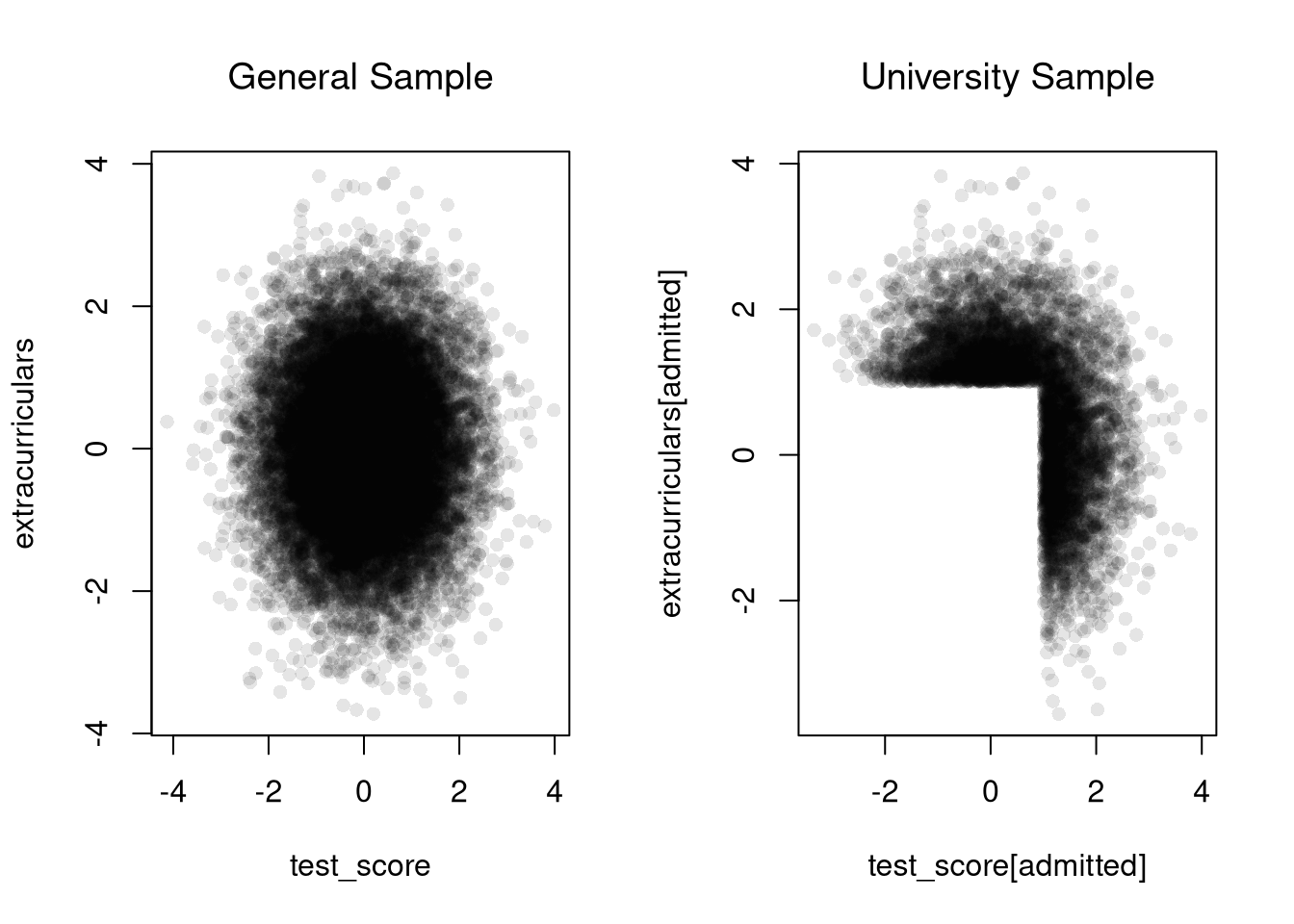
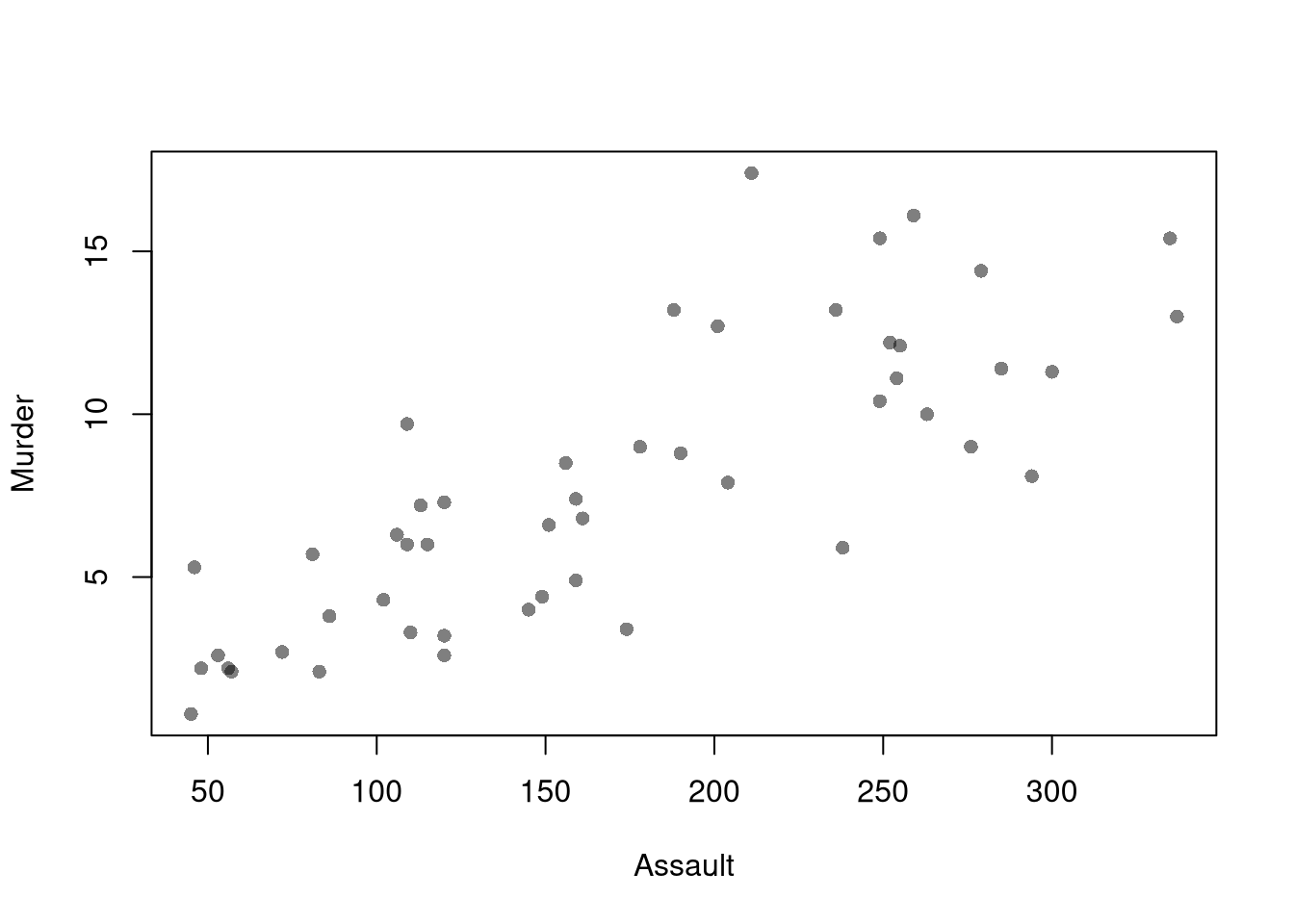
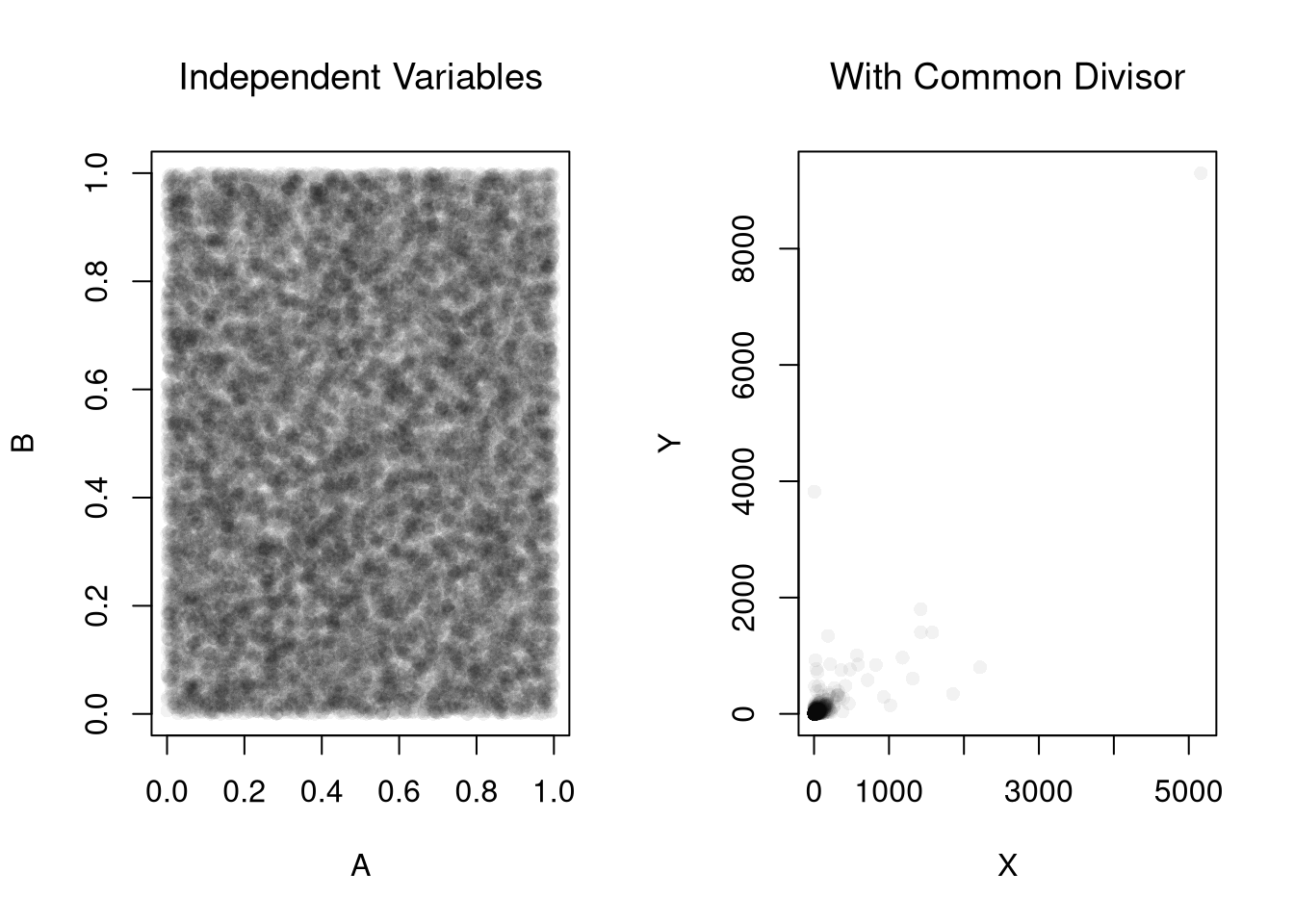
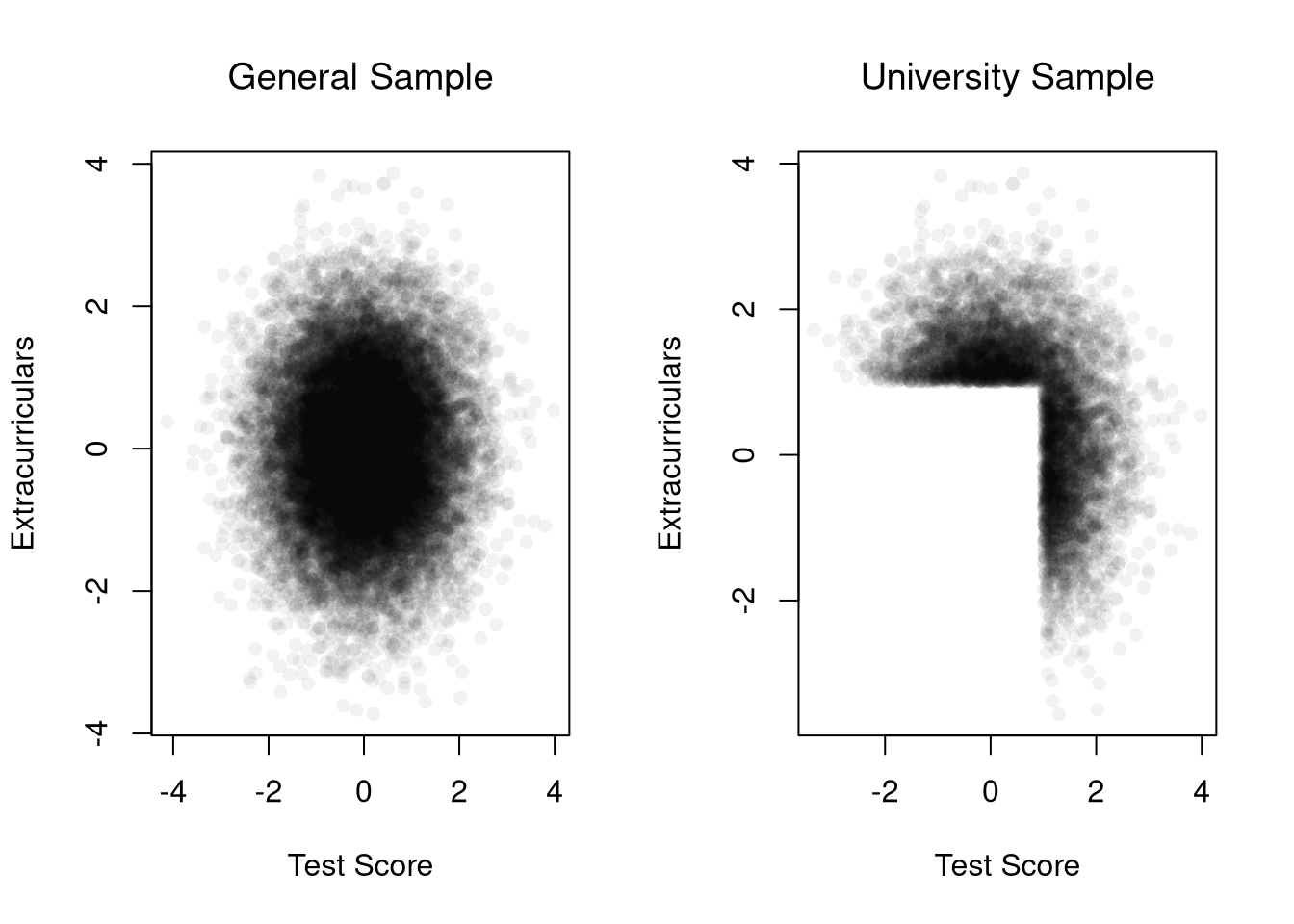
What is the correlation for the dataset \(\{ (0,0.1) , (1, 0.3), (2, 0.2) \}\)? Find the answer both mathematically and computationally.
Mathematically, there are five steps.
Step 1: Compute the means \[\begin{eqnarray}
\hat{M}_{X} &=& \frac{0+1+2}{3} = 1 \\
\hat{M}_{Y} &=& \frac{0.1+0.3+0.2}{3} = 0.2
\end{eqnarray}\]
Step 2: Compute the deviances \[\begin{eqnarray}
\begin{array}{c|rrrr}
\hat{X}_i & 0 & 1 & 2 \\
\hat{X}_i-\hat{M}_{X} & -1 & 0 & 1 \\
\hat{Y}_i & 0.1 & 0.3 & 0.2 \\
\hat{Y}_i-\hat{M}_{Y} & -0.1 & 0.1 & 0
\end{array}
\end{eqnarray}\]
Step 3: Compute the Covariance \[\begin{eqnarray}
\hat{C}_{XY} &=&
\sum (\hat{X}_i-\hat{M}_{X})(\hat{Y}_i-\hat{M}_{Y})/n
= \left[ (-1)(-0.1) + 0(0.1) + 1(0) \right] \frac{1}{3}
= (-0.1) \frac{1}{3}
= 1/30
\end{eqnarray}\]
Step 4: Compute Standard Deviations \[\begin{eqnarray}
\hat{V}_{X} &=& \sum_{i=1}^n \left(\hat{X}_i-\hat{M}_{X}\right)^2 / n
= \left[(-1)^2+0^2+1^2 \right]/3
= 2/3 \\
\hat{S}_{X} &=& \sqrt{2/3} \\
\hat{V}_{Y} &=& \sum_{i=1}^n \left( \hat{Y}_i-\hat{M}_{Y} \right)^2 / n
= \left[ (-0.1)^2+(0.1)^2+0^2 \right]/3
= \left[0.01+0.01\right]/3
= \frac{2}{100} \frac{1}{3} = 2/300 \\
\hat{S}_{Y} &=& \sqrt{2/300}
\end{eqnarray}\]
Step 5: Compute the Correlation \[\begin{eqnarray}
\frac{\hat{C}_{XY}}{\hat{S}_X \hat{S}_Y}
&=& \frac{1/30}{ \sqrt{2/3} \sqrt{2/300}}
= \frac{1/30}{ 2 /\sqrt{900}}
= \frac{1/30}{2/30} = 1/2
\end{eqnarray}\]
Note that this value suggests a positive relationship between the variables.
Computationally, we do the same steps
Code
# Create the Data
X <- c(0, 1, 2)
X
## [1] 0 1 2
Y <- c(0.1, 0.3, 0.2)
Y
## [1] 0.1 0.3 0.2
# Compute the Means
mX <- mean(X)
mY <- mean(Y)
# Compute the Deviances
dev_X <- X - mX
dev_Y <- Y - mY
# Compute the Covariance
cov_manual <- sum(dev_X * dev_Y) / length(X)
# Compute the Standard Deviations
var_X <- sum(dev_X^2) / length(X)
sd_X <- sqrt(var_X)
var_Y <- sum(dev_Y^2) / length(Y)
sd_Y <- sqrt(var_Y)
# Compute the Correlation
cor_manual <- cov_manual / (sd_X * sd_Y)
cor_manual
## [1] 0.5
# Verify with the built-in function
cor(X, Y)
## [1] 0.5