This chapter models how the average of \(\hat{Y}_{i}\) changes with \(\hat{X}_{i}\) without assuming a single straight line. We build up from regressograms (bin averages) to piecewise and local linear regression, carrying one running example throughout: wages and years of schooling. We close by measuring how well each model fits and introducing the bias-variance tradeoff.
Local Averages
Scatterplots are a great and simplest plot for bivariate data that simply plots each observation. There are many extensions and similar tools. The example below helps understand how both the central tendency and dispersion change.
Code
# Running example for the whole chapter: wages and years of schooling
library(Ecdat) # provides Wages1
# Scatter of every observation
plot(wage ~ school, data=Wages1, pch=16, col=grey(0, .1),
main=NA, xlab='School', ylab='Wage')
# Conditional mean at each integer schooling level
school_means <- aggregate(wage ~ school, data=Wages1, mean)
points(wage ~ school, data=school_means, # connect dots so the trend pops
pch=17, col=rgb(0, 0, 1, .8), type='b')
title('Grouped Means and Scatterplot', font.main=1)
Code
## Plot 2 (Alternative for big datasets)
# boxplot(wage ~ school, data=Wages1,
# pch=16, col=grey(0, .1), varwidth=T)
#title('Boxplots', font.main=1)
## Plot 3 (Less informative!)
#barplot(wage ~ school, data=school_means)
#title('Bar Plot of Grouped Means', font.main=1)
Examine the local relationship between ‘Murder’ and ‘Urbanization’ in the USArrests dataset. Use custom bins.
Code
xy <- USArrests[, c('Murder', 'UrbanPop')]
xy[, 'bins'] <- cut(USArrests[, 'UrbanPop'], 6)
To move beyond descriptive statistics, we will use models. We previously covered linear models, but you could be analyzing data with nonlinear relationships. So now we consider a general relationship: \[\begin{eqnarray}
\hat{Y}_{i} = m(\hat{X}_{i}) + e_{i},
\end{eqnarray}\] where \(m\) is an unknown function and \(e_{i}\) is white noise, which we estimate via different models. After minimizing the sum of squared errors in a the regressions below, our estimated models \(\hat{m}\) will also predict local averages.
Regressograms
Just as a histogram summarizes how observations are distributed across bins of \(X\), a regressogram summarizes how the conditional mean of \(\hat{Y}_{i}\) changes across bins of \(X\).
A regressogram splits \(X\) into exclusive intervals (bins) of half-width \(h\) and reports the average of \(\hat{Y}_{i}\) within each bin.
The regressogram is useful when we expect the relationship between \(X\) and \(Y\) to bend in ways a single line cannot capture, because the bin averages can rise, fall, or stay flat from one bin to the next without imposing any global shape. It is the conditional-mean analog of a histogram: histograms count observations within bins of \(X\); regressograms average \(Y\) within bins of \(X\).
Code
# Data
plot(wage ~ school, data=Wages1, pch=16, col=grey(0, .1),
main=NA, xlab='School', ylab='Wage')
dat <- Wages1[order(Wages1[, 'school']), c('wage', 'school')]
## Simple Regression
reg <- lm(wage ~ school, data=dat) ## OLS
# Regressogram: Course Age Bins
dat[, 'xcc'] <- cut(dat[, 'school'], 2)
rgram_c <- lm(wage ~ xcc, data=dat)
# Regressogram: Fine Age Bins
dat[, 'xcf'] <- cut(dat[, 'school'], 3)
rgram_f <- lm(wage ~ xcf, data=dat)
# Regressogram (Means for each level)
dat[, 'xd'] <- as.factor(dat[, 'school'])
rgram_d <- lm(wage ~ xd, data=dat)
## Compare Models (Only 2 for simplicity)
lines( dat[, 'school'], predict(reg), lwd=2, col=rgb(1, 0, 0, .8))
lines( dat[, 'school'], predict(rgram_f), lwd=2, col=rgb(0, 0, 1, .8), type='s')
legend('topleft',
legend=c('Linear Regression', 'Regressogram (3)'),
col=c(rgb(1, 0, 0, .8), rgb(0, 0, 1, .8)),
lty=1, cex=.8)
To conduct a regressogram, first divide \(X\) into \(1,...L\) exclusive bins of half-width \(h\). Each bin has a midpoint, \(x\), and each observation has an associated dummy variable \(\hat{D}_{i}(x,h) = \mathbf{1}\left(\hat{X}_{i} \in \left(x-h,x+h\right] \right)\).
The half-width \(h\) controls how “local” a local estimate actually is.
The bandwidth \(h\) is the half-width of a local bin around the design point \(x\): an observation is “local” to \(x\) when \(|\hat{X}_{i}-x|\leq h\).
The bandwidth is useful as the central tuning knob for every local method in this chapter: regressograms, piecewise regression, locally constant kernel regression, and locally linear regression. It is the same \(h\) that set the bin half-width of a histogram and the spread of a kernel density, except that there it controlled how much data went into a density estimate at \(x\), and here it controls how much data goes into a conditional-mean estimate at \(x\). It also tunes LOESS in the next chapter, in disguise as span. Larger \(h\) pools more observations into each estimate but smooths over real variation; smaller \(h\) tracks the data more closely but uses fewer points per estimate, so the fitted curve becomes noisier. Then we conduct a regression with this model: \[\begin{eqnarray}
\hat{Y}_{i} &=& \sum_{x \in \{x_{1}, ..., x_{L} \}} b_{0}(x,h) \hat{D}_{i}(x,h) + e_{i},
\end{eqnarray}\] where each bin has a coefficient \(b_{0}(x,h)\).
Local Averages.
When minimizing the sum of squared errors, the optimal coefficients are denoted as \(\hat{b}_{0}(x,h)\) and we can find them analytically. To do so, notice that each bin has \(n(x,h) = \sum_{i}^{n}\hat{D}_{i}(x,h)\) observations. This means we can split the dataset into parts associated with each bin \[\begin{eqnarray}
\sum_{i}^{n}\left[e_{i}\right]^2
&=& \sum_{i}^{n}\left[\hat{Y}_{i}- \sum_{x \in \{x_{1}, ..., x_{L} \}} b_{0}(x,h) \hat{D}_{i}(x,h) \right]^2 \\
&=& \sum_{i}^{n(x_{1},h)}\left[\hat{Y}_{i}- \sum_{x \in \{x_{1}, ..., x_{L} \}} b_{0}(x,h) \hat{D}_{i}(x,h) \right]^2
+ ... \sum_{i}^{n(x_{L},h)}\left[\hat{Y}_{i}- \sum_{x \in \{x_{1}, ..., x_{L} \}} b_{0}(x,h) \hat{D}_{i}(x,h) \right]^2 \\
&=& \sum_{i}^{n(x_{1},h)}\left[\hat{Y}_{i}- b_{0}\left(x_1,h\right) \right]^2 + ... \sum_{i}^{n(x_L,h)}\left[\hat{Y}_{i}-b_{0}\left(x_L,h\right) \right]^2 % +~ (N-1)\sum_{i}\hat{Y}_{i}.
\end{eqnarray}\] This separation allows us to analytically optimize for each bin separately \[\begin{eqnarray}
\min_{ \left\{ b_{0}(x,h) \right\} } \sum_{i}^{n}\left[e_{i}\right]^2
&=& \min_{ \left\{ b_{0}(x,h) \right\} } \sum_{i}^{n(x,h)}\left[\hat{Y}_{i}- b_{0}\left(x,h\right) \right]^2,
\end{eqnarray}\] In any case, minimizing yields the optimal coefficient as follows \[\begin{eqnarray}
0 &=& -2 \sum_{i}^{n(x,h)}\left[ \hat{Y}_{i} - b_{0}(x,h) \right] \\
\hat{b}_{0}(x,h) &=& \frac{\sum_{i}^{n(x,h)} \hat{Y}_{i}}{ n(x,h) } = \hat{M}_{Y}(x,h).
\end{eqnarray}\] As such, the OLS regression yields coefficients that are interpreted as the conditional mean: \(\hat{M}_{Y}(x,h)\). We can directly compute the same statistic directly by simply taking the average value of \(\hat{Y}_{i}\) for all \(i\) observations in a particular bin.
In any case, the values predicted by the model are found as \[\begin{eqnarray}
\hat{y}_{i} = \sum_{x} \hat{b}_{0}(x,h) \hat{D}_{i}(x,h) = \sum_{x} \hat{M}_{Y}(x,h) \hat{D}_{i}(x,h).
\end{eqnarray}\] I.e., the predicted value of observation \(i\) is the the average value for its bin.
Consider this two-bin regressogram example of how schooling affects wage for people with \(\leq 9\) years of school completed vs \(> 9\). \[\begin{eqnarray}
\text{Wage}_{i} &=& b_{0}(x=4.5, h=9/2) \mathbf{1}\left(\text{Educ}_{i} \in (0,9]\right) + b_{0}(x=13.5, h=9/2) \mathbf{1}\left(\text{Educ}_{i} \in (9,18] \right) + e_{i}.
\end{eqnarray}\]
Here is a simple example with three data points \((\hat{X}_{i}, \hat{Y}_{i}) \in \{ (1,2), (4,4), (12,3) \}\), we can easily compute \[\begin{eqnarray}
n(x=4.5,h=9/2) &=& 2\\
\hat{b}_{0}(x=4.5, h=9/2) &=& [2 + 4] / 2 \\
n(x=13.5,h=9/2) &=& 1\\
\hat{b}_{0}(x=13.5, h=9/2) &=& 3 / 1
\end{eqnarray}\]
Here is a simple example with data
Code
pred_c <- predict(rgram_c)
pred_dat <- data.frame(xcc=dat$xcc, pred=round(pred_c, 6))
table(pred_dat)
## pred
## xcc 4.115873 5.917872
## (2.99,9.5] 293 0
## (9.5,16] 0 3001
## Compare to simple aggregation
aggregate(wage ~ xcc, data=dat, mean)
## xcc wage
## 1 (2.99,9.5] 4.115873
## 2 (9.5,16] 5.917872
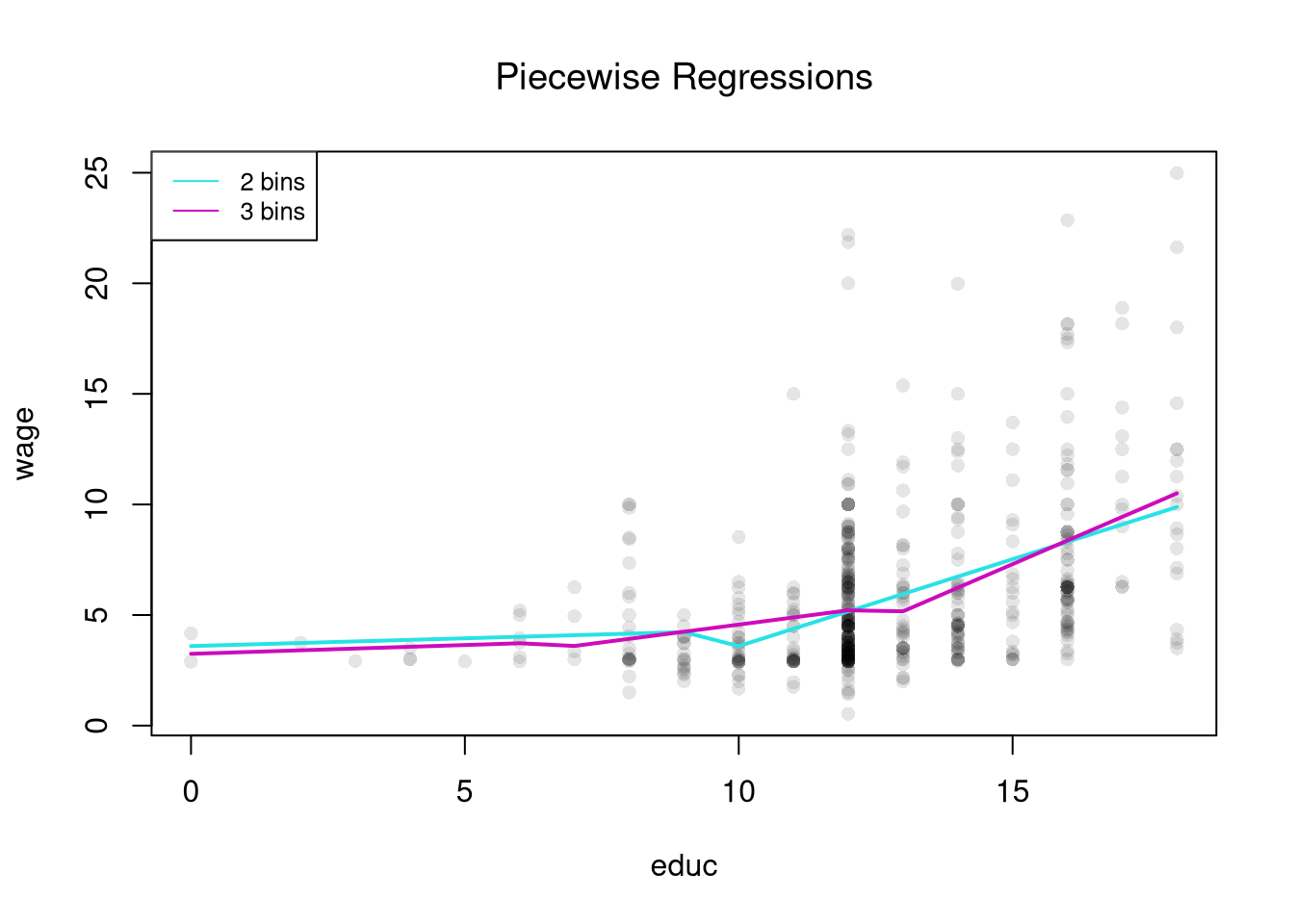
Piecewise Regression
To let the slope vary across the range of \(X\) instead of just the level, we add a slope term within each bin.
A piecewise regression (also segmented regression) divides \(X\) into bins and runs a separate simple linear regression on each bin. Within a bin the relationship is a straight line; across bins the slope and intercept can change.
Piecewise regression is useful when the relationship is approximately linear in pieces but the slope itself changes. Returns to schooling might flatten after a degree, for example, or marginal cost curves might kink at capacity. Compared to the regressogram, it captures within-bin trends instead of just within-bin averages; compared to a single line, it lets the slope bend at bin boundaries.
Code
# Data
plot(wage ~ school, data=Wages1, pch=16, col=grey(0, .1),
main=NA, xlab='School', ylab='Wage')
dat <- Wages1[order(Wages1[, 'school']), c('wage', 'school')]
# Piecewise: Course Age Bins
dat[, 'xcc'] <- cut(dat[, 'school'], 2)
preg_c <- lm(wage ~ xcc*school, data=dat)
# Piecewise: Fine Age Bins
dat[, 'xcf'] <- cut(dat[, 'school'], 3)
preg_f <- lm(wage ~ xcf*school, data=dat)
## Compare Models
pw_cols <- hcl.colors(3, alpha=.75)
lines( dat[, 'school'], predict(preg_c), lwd=2, col=pw_cols[1])
lines( dat[, 'school'], predict(preg_f), lwd=2, col=pw_cols[2])
legend('topleft',
legend=c('2 bins', '3 bins'),
lty=1, col=pw_cols[1:2], cex=.8)
title('Piecewise Regressions', font.main=1)
The model is \[\begin{eqnarray}
\hat{Y}_{i} &=& \sum_{x} \left[b_{0}(x,h) + b_{1}(x,h)\hat{X}_{i} \right] \hat{D}_{i}(x,h) + e_{i}.
\end{eqnarray}\] This same separation as above allows us to analytically optimize for each bin separately. I.e. we run separate regressions on the split samples. From the previous chapter on simple linear regression, we know the solutions are \[\begin{eqnarray}
\hat{b}_{0}(x,h) &=& \hat{M}_{Y}(x,h)-\hat{b}_{1}\hat{M}_{X}(x,h)\\
\hat{b}_{1}(x,h) &=& \frac{\sum_{i}^{n(x,h)}(\hat{X}_{i}-\hat{M}_{X}(x,h))(\hat{Y}_{i}-\hat{M}_{Y}(x,h))}{\sum_{i}^{n(x,h)}(\hat{X}_{i}-\hat{M}_{X}(x,h))^2} = \frac{\hat{C}_{XY}(x,h)}{\hat{V}_{X}(x,h)},
\end{eqnarray}\]
Code
# See that two methods give the same predictions
# Piecewise: Course Age Bins
dat[, 'xcc'] <- cut(dat[, 'school'], 2)
preg_c <- lm(wage ~ xcc*school, data=dat)
pred2 <- predict(preg_c)
## Split Sample Regressions
dat2 <- split( dat, dat[, 'xcc'])
pred2B <- vector('list', length(dat2))
names(pred2B) <- names(dat2)
for (i in seq_along(dat2)) {
reg2 <- lm(wage ~ school, dat2[[i]])
pred2B[[i]] <- predict(preg_c)
}
# Any differences?
all( pred2 - unlist(pred2B) < 1e-10 )
## [1] TRUE
Compare a simple regression to a regressogram and a piecewise regression. Examine the relationship between ‘Murder’ and ‘Urbanization’ in the USArrests dataset.
Code
xy <- USArrests[, c('Murder', 'UrbanPop')]
colnames(xy) <- c('y', 'x')
# Globally Linear
reg <- lm(y ~ x, data=xy)
Try to do so on your own before looking at the code below, which compares two piecewise regressions to a simple linear regression.
Code
# Diagnose Fit
#plot( fitted(reg), resid(reg), pch=16, col=grey(0, .5))
#plot( xy[, 'x'], resid(reg), pch=16, col=grey(0, .5))
# Linear in 2 Pieces (subsets)
xcut2 <- cut(xy[, 'x'], 2)
xy_list2 <- split(xy, xcut2)
regs2 <- vector('list', length(xy_list2))
names(regs2) <- names(xy_list2)
for (i in seq_along(xy_list2)) {
regs2[[i]] <- lm(y ~ x, data=xy_list2[[i]])
}
# Linear in 3 Pieces (subsets or bins)
xcut3 <- cut(xy[, 'x'], seq(32, 92, by=20)) # Finer Bins
xy_list3 <- split(xy, xcut3)
regs3 <- vector('list', length(xy_list3))
names(regs3) <- names(xy_list3)
for (i in seq_along(xy_list3)) {
regs3[[i]] <- lm(y ~ x, data=xy_list3[[i]])
}
## Make Predictions
pred1 <- data.frame(yhat=predict(reg),
x=reg[['model']][, 'x'])
pred1 <- pred1[order(pred1[, 'x']), ]
pred2 <- vector('list', length(regs2))
for (i in seq_along(regs2)) {
pred2[[i]] <- data.frame(yhat=predict(regs2[[i]]),
x=regs2[[i]][['model']][, 'x'])
}
pred2 <- do.call(rbind, pred2)
pred2 <- pred2[order(pred2[, 'x']), ]
pred3 <- vector('list', length(regs3))
for (i in seq_along(regs3)) {
pred3[[i]] <- data.frame(yhat=predict(regs3[[i]]),
x=regs3[[i]][['model']][, 'x'])
}
pred3 <- do.call(rbind, pred3)
pred3 <- pred3[order(pred3[, 'x']), ]
# Compare Predictions
plot(y ~ x, pch=16, col=grey(0, .5), data=xy)
lines(yhat ~ x, pred1, lwd=2, col=2)
lines(yhat ~ x, pred2, lwd=2, col=4)
lines(yhat ~ x, pred3, lwd=2, col=3)
legend('topleft',
legend=c('Globally Linear',
'Piecewise Linear (2)',
'Piecewise Linear (3)'),
lty=1, col=c(2, 4, 3), cex=.8)
For many things, a simple linear regression, regressograms, or piecewise regression is “good enough”. Simple linear regressions struggle with nonlinear relationships but are very easy to run with a computer. Regressograms and piecewise regressions are intuitive ways to capture nonlinear relationships that are computationally efficient but have obvious problems where the bins change. Sometimes we want smoother predictions or to estimate derivatives (gradients). To cover more advanced regression methods that do those things, we will need to first learn about kernel density estimation.
Weighted Regression.
Interestingly, we can obtain the same statistics from weighted least squares regression. For some specific design point, \(x\), we can find \(\hat{b}(x, h)\) by minimizing \[\begin{eqnarray}
\sum_{i}^{n}\left[ e_{i} \right]^2 \hat{D}_{i}(x,h) &=& \sum_{i}^{n}\left[ \hat{Y}_{i}- b_{0}(x,h) - b_{1}(x,h) \hat{X}_{i} \right]^2 \hat{D}_{i}(x,h) \\
&=& \sum_{i}^{n(x_{1},h)}\left[ \hat{Y}_{i}- b_{0}(x_{1},h) - b_{1}(x_{1},h) \hat{X}_{i} \right]^2 \hat{D}_{i}(x_{1},h) + ... \sum_{i}^{n(x_{L},h)}\left[ \hat{Y}_{i}- b_{0}(x_{L},h) - b_{1}(x_{L},h) \hat{X}_{i} \right]^2 \hat{D}_{i}(x_{L},h) \\
&=& \sum_{i}^{n(x,h)}\left[\hat{Y}_{i}- b_{0}\left(x,h\right) - b_{1}(x,h) \hat{X}_{i} \right]^2
\end{eqnarray}\]
We get nearly identical results if we instead use “uniform weights” with half-width \(h\), \[\begin{eqnarray}
k_{U}\left( \hat{X}_{i}, x, h \right)
&=& \frac{\mathbf{1}\left(\frac{|\hat{X}_{i}-x|}{h} \leq 1\right)}{2}
= \frac{\mathbf{1}\left( \hat{X}_{i} \in \left[ x-h, x + h\right] \right) }{2} \\
\end{eqnarray}\] with is nearly identical to \(\hat{D}_{i}(x,h)/ 2\), but uses intervals \([]\) instead of \((]\). As such we can see that \[\begin{eqnarray}
\sum_{i}^{n}\left[ e_{i} \right]^2 k_{U}\left( \hat{X}_{i}, x, h \right)
&\approx& \sum_{i}^{n}\left[ e_{i} \right]^2 \hat{D}_{i}(x,h) / 2 \\
&=& \sum_{i}^{n(x,h)}\left[\hat{Y}_{i}- b_{0}\left(x,h\right) - b_{1}(x,h) \hat{X}_{i} \right]^2 / 2,
\end{eqnarray}\] The constant term \(1/2\) is irrelevant to finding the optimal solution (you can check the math yourself).
Here is an example going into the details of the weights.
Code
## Generate Sample Data
x <- 1:5
y <- round( rnorm(length(x)) , 2)
y
## [1] -1.06 0.69 -0.86 -0.39 0.12
## plot(x, y)
## Manually Compute Estimate at x=3
h <- 1
k3_weights <- dunif( abs(x-3)/h, -1, 1) #(x >= 2)*(x <= 4)
k3_weights
## [1] 0.0 0.5 0.5 0.5 0.0
# Divide by the total so the weights sum to one
w3 <- k3_weights/sum(k3_weights)
yhat_3 <- sum(w3*y)
yhat_3
## [1] -0.1866667
# Equals the simple average of the y's within h of x=3
mean( y[ abs(x-3) <= h ] )
## [1] -0.1866667
Code
library(Ecdat) # Data from before
dat <- Wages1[order(Wages1[, 'school']), c('wage', 'school')]
## Weighted Regression
x <- 4.5
h <- 9.036/2 #makes bin large enough to include 0: (-0.018, 9]
k <- abs(dat[, 'school']-x) /h
k_weights <- dunif(k, -1, 1) # the uniform kernel k_U
preg_k <- lm(wage ~ school, data=dat, weights=k_weights)
predict(preg_k, newdata=data.frame(school=x))
## 1
## 4.551132
# Compare to Piecewise
dat[, 'xcc'] <- cut(dat[, 'school'], 2)
preg_c <- lm(wage ~ xcc*school, data=dat)
predict(preg_c, newdata=data.frame(school=x, xcc='(9.5,16]'))
## 1
## 1.090272
Locally Constant Regression
By replacing the hard bin indicator with a smooth kernel weight, we can fit a local average at every design point and get a curve that varies continuously with \(x\).
A locally constant (kernel) regression fits a single constant at each design point \(x\) by minimizing a kernel-weighted sum of squared residuals: \[\min_{b_{0}(x, h)} \sum_{i=1}^{n}\left[\hat{Y}_{i} - b_{0}(x, h) \right]^{2} k\left(\hat{X}_{i}, x, h\right),\] where \(k(\hat{X}_{i}, x, h)\) is a kernel weight that down-weights observations far from \(x\).
The locally constant regression is useful as the simplest smoother that produces a continuous fitted curve: at each \(x\) it returns a kernel-weighted average of nearby \(\hat{Y}_{i}\). With a uniform kernel and exclusive bins it reduces to a regressogram, so the regressogram is just its simplest special case.
For some intuition, consider a point \(x\) and the model \(\hat{Y}_{i} = b_{0}(x, h) + e_{i}\). The weighted OLS estimator with uniform kernel weights \(k_{U}\) yields \[\begin{eqnarray}
& & \min_{b_{0}(x,h)}~ \sum_{i}^{n}\left[e_{i} \right]^2 k_{U}\left( \hat{X}_{i}, x, h \right) \\
\Rightarrow & & -2 \sum_{i}^{n}\left[\hat{Y}_{i}- b_{0}(x, h) \right] k_{U}\left(\hat{X}_{i}, x, h\right) = 0\\
\Rightarrow & & \hat{b}_{0}(x)
= \frac{\sum_{i} \hat{Y}_{i} k_{U} \left( \hat{X}_{i}, x, h \right) }{ \sum_{i} k_{U}\left( \hat{X}_{i}, x, h \right) }
= \sum_{i} \hat{Y}_{i} \left[ \frac{ k_{U} \left( \hat{X}_{i}, x, h \right) }{ \sum_{i} k_{U}\left( \hat{X}_{i}, x, h \right)} \right]
= \sum_{i} \hat{Y}_{i} w_{i}(x, h),
\end{eqnarray}\] where weights are determined from \[\begin{eqnarray}
\sum_{i}^{n} k_{U} \left( \hat{X}_{i}, x, h \right) &=& \sum_{i}^{n(x,h)} k_{U} \left( \hat{X}_{i}, x, h \right) + \sum_{i}^{n - n(x,h)} 0 = \frac{n(x, h)}{2}\\
w_{i}(x, h) &=& \left[ \frac{ k_{U} \left( \hat{X}_{i}, x, h \right) }{ \sum_{i} k_{U}\left( \hat{X}_{i}, x, h \right)} \right]
= \frac{\mathbf{1}\left( |\hat{X}_{i} - x| \leq h \right)}{n(x, h)}
\end{eqnarray}\] So locally constant kernel regression recovers the weighted mean of \(Y_{i}\) around design point \(x\). If we use exclusive bins, then we are essentially running a regressogram. As such, the regressogram is more crude but can be estimated more easily.
See how the results are nearly identical below. Then consider different design points.
Code
#library(Ecdat) # Data from before
#dat <- Wages1[order(Wages1[, 'school']), c('wage', 'school')]
# Piecewise Regression
dat[, 'xcc'] <- cut(dat[, 'school'], 2)
preg_c <- lm(wage ~ xcc*school, data=dat)
predict(preg_c, newdata=data.frame(school=x, xcc='(9.5,16]'))
## 1
## 1.090272
## Weighted Regression
x <- 4.5 # regressogram bin1 midpoint
h <- 9.036/2 #regressogram half-width
k_weights <- dunif( abs(dat[, 'school']-x)/h, -1, 1)
preg_k <- lm(wage ~ school, data=dat, weights=k_weights)
predict(preg_k, newdata=data.frame(school=x))
## 1
## 4.551132
Notes.
When \(n\) is small, \(\hat{b}_{U}(x, h)\) is typically estimated for each unique observed value: \(x \in \{ x_{1},...x_{n} \}\). For large datasets, you can select a subset or evenly spaced values of \(x\) for which to make predictions.
If \(\hat{X}_{i}\) represents time, then the local constant regressions is also called a moving average. We can create a weighted moving average by using a different distribution. I.e. using the Normal dnorm instead of the Uniform dunif.
The basic idea also generalizes other kernels. As such, a kernel regression using uniform weights is often called a “naive kernel regression”. Typically, kernel regressions use kernels that weight nearby observations more heavily.
Bias
The regressogram has a bias at the edges of the bins, which is addressed by the local constant regression. Still, the local constant regression has a bias near the edges of the dataset. (The kernel divides by \(2h\) assuming there is data on both sides of the design point). This can be addressed by renormalizing weights.
Here is an example going into the details of the weights.
Code
## Generate Sample Data
X <- 1:5
Y <- rnorm(length(X))
Y
## [1] -1.2429800 1.3769665 0.7766744 0.5247062 1.9087103
## Manually Compute Estimate at x=5
h <- 2
k5_weights <- dunif( abs(X-5)/h, -1, 1) #(X >= 3)*(X =< 7)/2
k5_weights
## [1] 0.0 0.0 0.5 0.5 0.5
yhat_5 <- sum(k5_weights*Y)
yhat_5
## [1] 1.605045
## Edge Correction
k5_weights_ec <- k5_weights/sum(k5_weights)
yhat_5_ec <- sum(k5_weights_ec*Y)
yhat_5_ec
## [1] 1.07003
We can also add a slope term to address the bias.
Local Linear Regression
A less simple case is a local linear regression which conducts a linear regression for each data point using a subsample of data around it. Consider a point \(x\) and model \(\hat{Y}_{i} = b_{0}(x,h) + b_{1}(x) \hat{X}_{i} + e_{i}\) for data near \(x\). The weighted OLS estimator with kernel weights is \[\begin{eqnarray}
& & \min_{b_{0}(x, h),b_{1}(x, h)}~ \sum_{i}^{n}\left[\hat{Y}_{i}- b_{0}(x, h) - b_{1}(x,h) \hat{X}_{i} \right]^2 k_{U}\left( \hat{X}_{i}, x, h\right)
\end{eqnarray}\] Deriving the optimal values \(\hat{b}_{0}(x, h)\) and \(\hat{b}_{1}(x,h)\) for \(k_{U}\) is left as a homework exercise.
Code
# ``Naive" Smoother
pred_fun <- function(x0, h){
# Assign equal weight to observations within h distance to x0
# 0 weight for all other observations
ki <- abs(dat[, 'school']-x0)/h
ki <- dunif(ki, -1, 1) ## The uniform kernel k_U; could change, e.g. dnorm(ki)
wi <- ki/sum(ki, na.rm=TRUE) # always sum to 1 (for edge-effects)
# run regression with weighted data
llls_i <- lm(wage ~ school, data=dat, weights=wi)
yhat_i <- predict(llls_i, newdata=data.frame(school=x0))
}
X0 <- seq(4, 16, by=1) # Design points
# Fine Bins
pred_lo1 <- rep(NA, length(X0))
for(i in seq_along(X0)){
pred_lo1[i] <- pred_fun(x0=X0[i], h=2)
}
# Course Bins
pred_lo2 <- rep(NA, length(X0))
for(i in seq_along(X0)){
pred_lo2[i] <- pred_fun(x0=X0[i], h=6)
}
# Plot
plot(wage ~ school, pch=16, data=Wages1, col=grey(0, .1),
main=NA, ylab='Wage', xlab='School')
cols <- c(rgb(.8, 0, 0, .5), rgb(0, 0, .8, .5))
lines(X0, pred_lo1, col=cols[1], lwd=1, type='o')
lines(X0, pred_lo2, col=cols[2], lwd=1, type='o')
legend('topleft', title='Locally Linear',
legend=c('h=2', 'h=6'),
lty=1, col=cols, cex=.8)
Compare local linear and local constant regressions using https://shinyserv.es/shiny/kreg/, with degree \(0\) and \(1\). Also try different kernels and different datasets.
Examine the local relationship between ‘Murder’ and ‘Urbanization’ in the USArrests dataset using LLLS.
Code
xy <- USArrests[, c('Murder', 'UrbanPop')]
X0 <- sort(unique(xy[, 'UrbanPop']))
plot(y ~ x, pch=16, data=xy, col=grey(0, .5),
ylab='Murder Rate', xlab='Population Density')
pred_lo1 <- numeric(length(X0))
for (i in seq_along(X0)) {
pred_lo1[i] <- pred_fun(X0[i], h=2, xy=xy)
}
pred_lo2 <- numeric(length(X0))
for (i in seq_along(X0)) {
pred_lo2[i] <- pred_fun(X0[i], h=20, xy=xy)
}
cols <- c(rgb(.8, 0, 0, .5), rgb(0, 0, .8, .5))
lines(X0, pred_lo1, col=cols[1], lwd=1, type='o')
lines(X0, pred_lo2, col=cols[2], lwd=1, type='o')
legend('topleft', title='Locally Linear',
legend=c('h=2 ', 'h=20'),
lty=1, col=cols, cex=.8)
Exercises
Comment the script you wrote for this chapter, then restart R and check that it runs from a clean session, then check the script with AI as explained in Working with AI. Write three sentences from memory on the main statistical idea of this chapter, and ask the assistant what is wrong, vague, or missing. Finish with your own questions about whatever you found hardest.
Explain the difference between a regressogram and a local linear regression. In what sense does increasing the number of bins in a regressogram create a bias-variance tradeoff?
Using the Wages1 dataset from the Ecdat package, fit a regressogram with 4 bins and a piecewise regression with 4 bins for the relationship between wage and school. Compute the predicted value at school = 10 for each model.
Using the USArrests dataset, write R code to estimate a local linear regression of Murder on UrbanPop using uniform kernel weights with bandwidth \(h = 10\). Compute predictions at design points X0 <- seq(40, 80, by = 10) and plot them over the scatterplot.
The chapter derives the optimal locally constant coefficient \(\hat{b}_{0}(x,h)\) but leaves the local linear case as an exercise. Starting from the weighted objective \(\sum_{i} [\hat{Y}_{i} - b_{0} - b_{1}\hat{X}_{i}]^2 \, k_{U}(\hat{X}_{i}, x, h)\), set the partial derivatives with respect to \(b_{0}\) and \(b_{1}\) to zero. Show that the solution is the simple-regression formula applied to the kernel-weighted data: \(\hat{b}_{1}(x,h) = \hat{C}_{XY}(x,h)/\hat{V}_{X}(x,h)\) and \(\hat{b}_{0}(x,h) = \hat{M}_{Y}(x,h) - \hat{b}_{1}(x,h)\hat{M}_{X}(x,h)\).
Recall
This chapter let the wage-schooling relationship bend by fitting local models on the Wages1 data: regressograms (bin means), piecewise regression (bin lines), locally constant kernel regression, and locally linear regression. The three-observation worked example \(\{(1, 2), (4, 4), (12, 3)\}\) split into two bins at \(h=9/2\) gave regressogram coefficients \(\hat{b}_{0}(x=4.5)=(2+4)/2=3\) and \(\hat{b}_{0}(x=13.5)=3\). The next chapter asks how to evaluate these fits and how much they vary across samples: model-fit metrics (\(\hat{MSE}\) and \(\hat{MAPE}\)), the bias-variance tradeoff, bootstrap confidence bands, gradient summaries, and consistency.