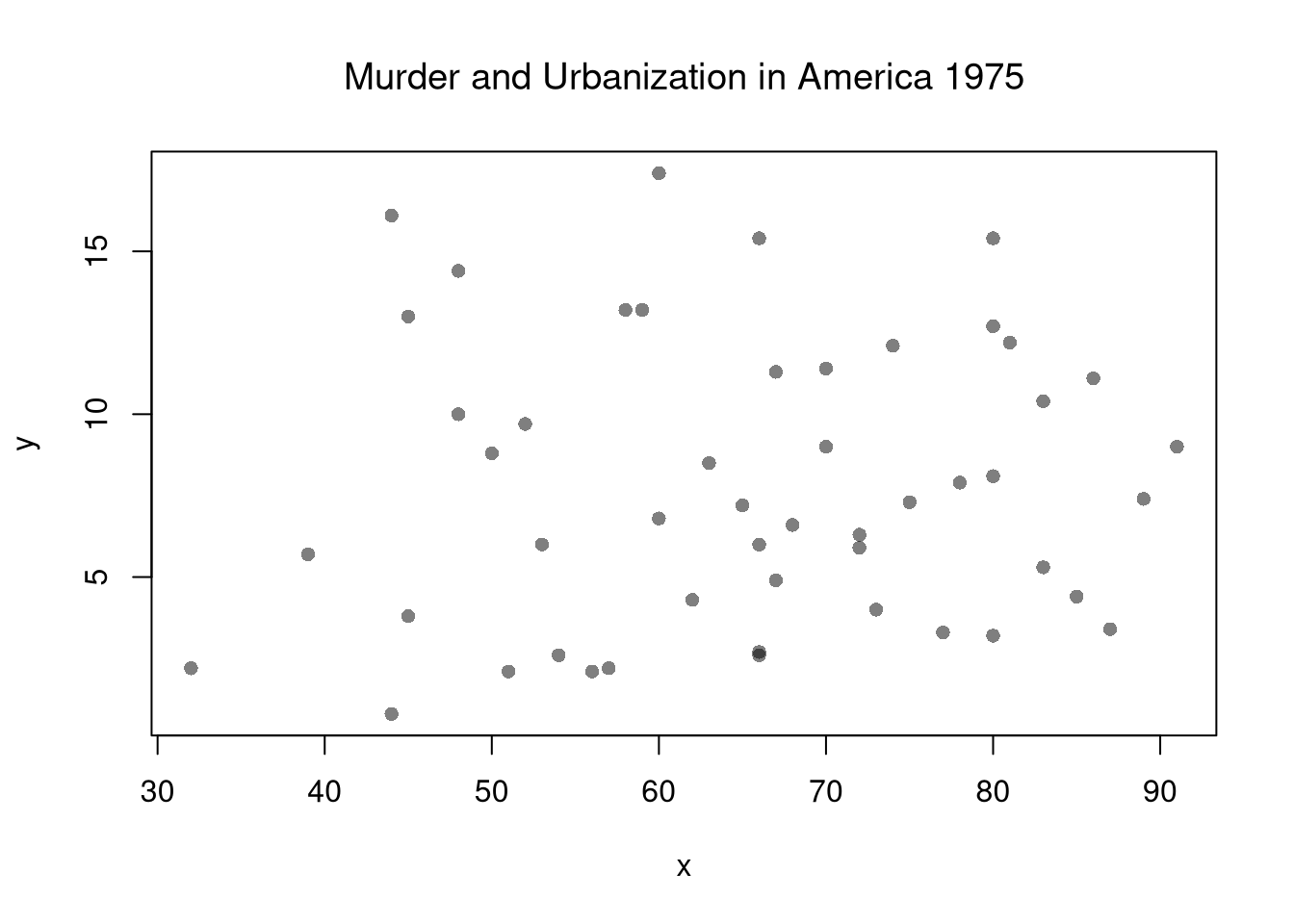
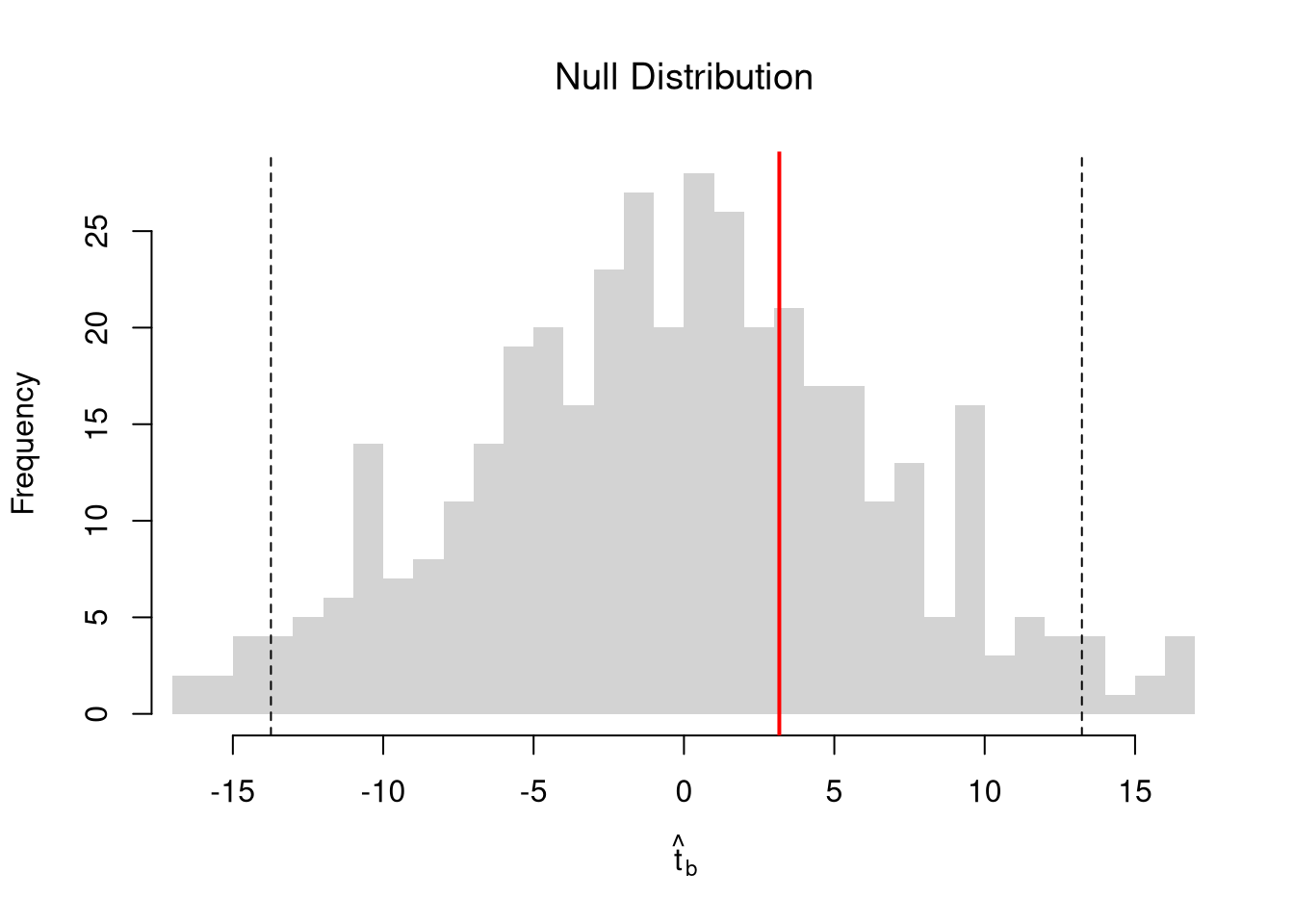
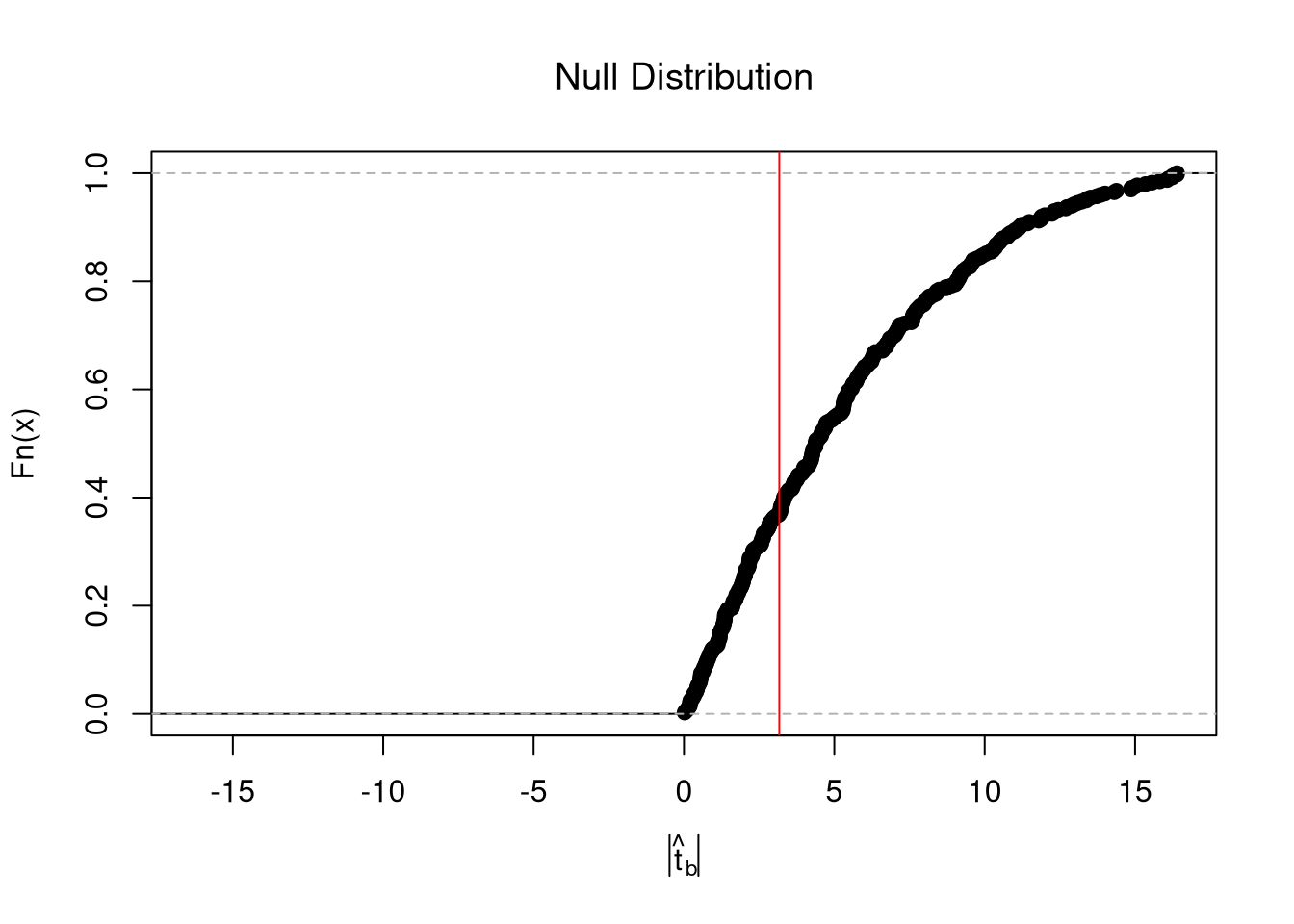
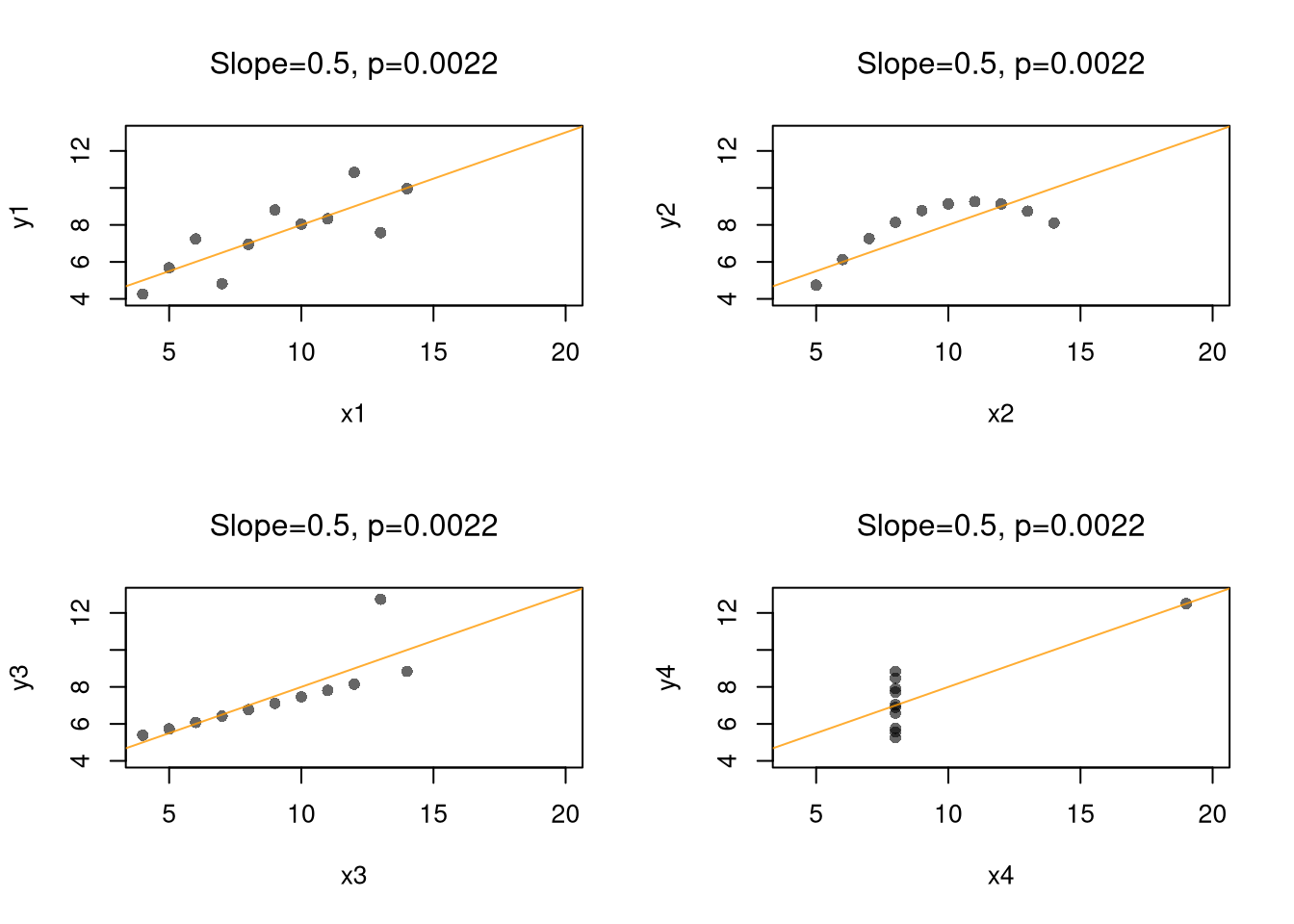
We use the dataset \(\{(1,2), (2,2.5), (3,4)\}\) to compute Goodness of fit.
From before, we know that \(\hat{M}_Y = \frac{17}{6}\) and the fitted values and residuals from the regression are \[\begin{eqnarray}
\hat{y}_1 = \frac{11}{6},\qquad
\hat{y}_2 = \frac{17}{6},\qquad
\hat{y}_3 = \frac{23}{6}.\\
\hat{e}_1 = \frac{1}{6},\qquad
\hat{e}_2 = -\frac{1}{3},\qquad
\hat{e}_3 = \frac{1}{6}.
\end{eqnarray}\]
Step 1. Total Sum of Squares (TSS)
\[\begin{eqnarray}
\hat{Y}_1 - \hat{M}_Y &=& 2 - \frac{17}{6} = -\frac{5}{6},\\
\hat{Y}_2 - \hat{M}_Y &=& 2.5 - \frac{17}{6} = -\frac{1}{3},\\
\hat{Y}_3 - \hat{M}_Y &=& 4 - \frac{17}{6} = \frac{7}{6}.
\end{eqnarray}\]
\[\begin{eqnarray}
\hat{TSS} &=& \sum_{i} (\hat{Y}_i - \hat{M}_Y)^2 \\
&=& \left(-\frac{5}{6}\right)^2
+ \left(-\frac{1}{3}\right)^2
+ \left(\frac{7}{6}\right)^2 \\
&=& \frac{25}{36} + \frac{1}{9} + \frac{49}{36}
= \frac{78}{36}
= \frac{13}{6}.
\end{eqnarray}\]
Step 2. Explained Sum of Squares (ESS)
\[\begin{eqnarray}
\hat{y}_1 - \hat{M}_Y = -1,\qquad
\hat{y}_2 - \hat{M}_Y = 0,\qquad
\hat{y}_3 - \hat{M}_Y = 1.
\end{eqnarray}\]
\[\begin{eqnarray}
\hat{ESS}
= \sum_i (\hat{y}_i - \hat{M}_Y)^2
= (-1)^2 + 0^2 + 1^2 = 2.
\end{eqnarray}\]
Step 3. Residual Sum of Squares (RSS)
\[\begin{eqnarray}
\hat{RSS}
= \sum_{i} \hat{e}_i^2
= \left(\frac{1}{6}\right)^2
+ \left(-\frac{1}{3}\right)^2
+ \left(\frac{1}{6}\right)^2.
\end{eqnarray}\]
\[\begin{eqnarray}
\hat{RSS}
= \frac{1}{36} + \frac{1}{9} + \frac{1}{36}
= \frac{1}{36} + \frac{4}{36} + \frac{1}{36}
= \frac{6}{36}
= \frac{1}{6}.
\end{eqnarray}\]
Step 4. Check the Decomposition
\[\begin{eqnarray}
\hat{ESS} + \hat{RSS}
= 2 + \frac{1}{6}
= \frac{12}{6} + \frac{1}{6}
= \frac{13}{6}
= \hat{TSS}.
\end{eqnarray}\]
Step 5. Coefficient of Determination
\[\begin{eqnarray}
\hat{R}_{yY}^2
= \frac{\hat{ESS}}{\hat{TSS}}
= \frac{2}{13/6}
= \frac{12}{13}
\approx 0.9
\end{eqnarray}\]
(Verification) \[\begin{eqnarray}
1 - \frac{\hat{RSS}}{\hat{TSS}}
= 1 - \frac{1/6}{13/6}
= 1 - \frac{1}{13}
= \frac{12}{13}.
\end{eqnarray}\]
Code
# Compute R2
Ehat0 <- resid(reg0)
RSS0 <- sum(Ehat0^2)
Y0 <- xy0[, 'y']
TSS0 <- sum((Y0-mean(Y0))^2)
R2 <- 1 - RSS0/TSS0
# compare with our calculation: 12/13
# compare with our intuitive benchmark
cor(Y0, predict(reg0))
## [1] 0.9607689