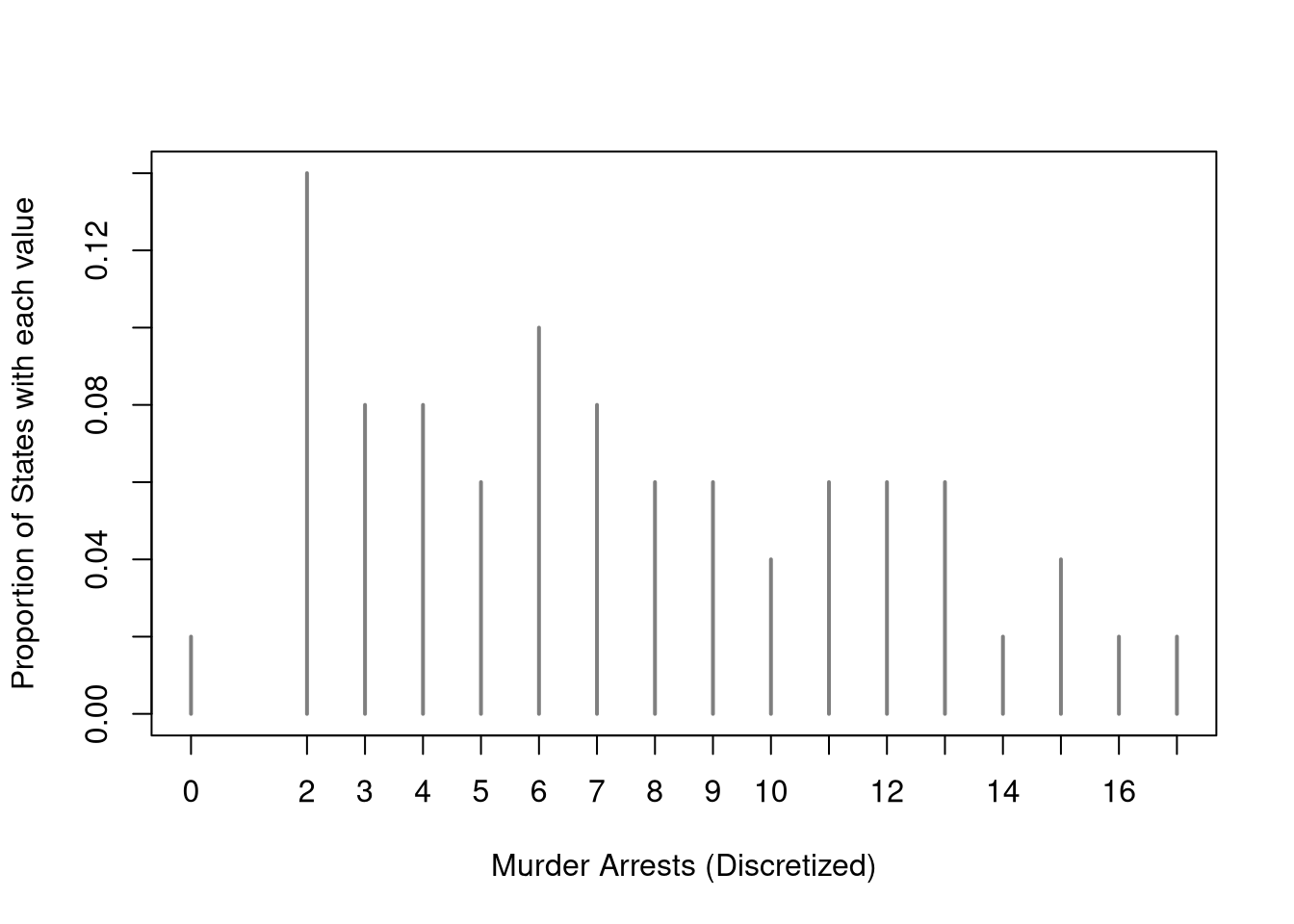
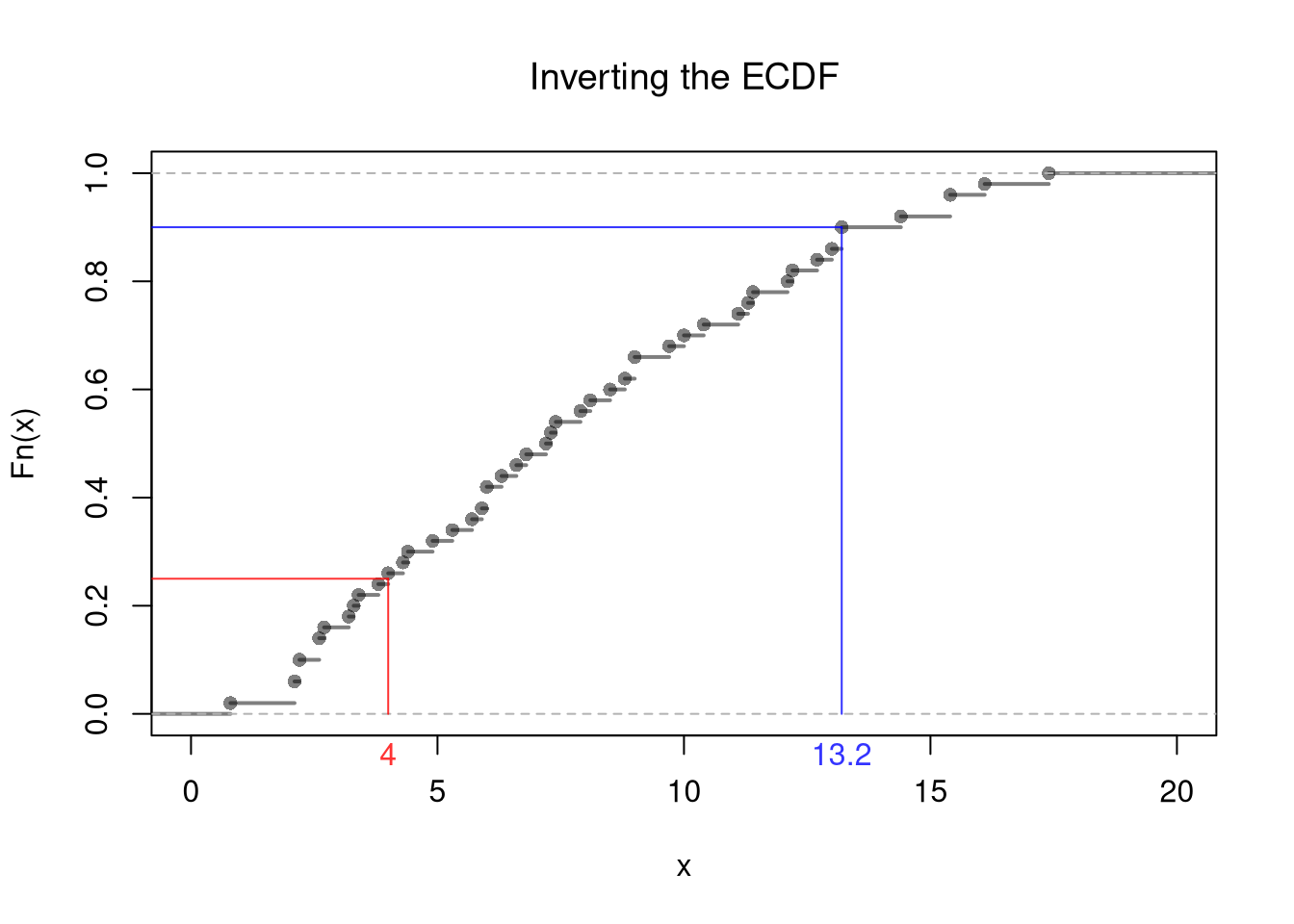
For example, consider the dataset \(\{3,3.1,0.02\}\) and use bins \((0,1], (1,2], (2,3], (3,4]\). In this case, the midpoints are \(x=(0.5,1.5,2.5,3.5)\) and \(h=1/2\). Then the counts at each midpoints are \((1,0,1,1)\). Since \(\frac{1}{n 2h}=\frac{1}{3\times1}=\frac{1}{3}\), we can rescale the counts to compute the density as \(\hat{f}(x)=(1,0,1,1) \frac{1}{3}=(1/3,0,1/3,1/3)\).
Code
# Intuitive Examples
X <- c(3, 3.1, 0.02)
Xhist <- hist(X, breaks=c(0, 1, 2, 3, 4), plot=FALSE, freq=FALSE)
Xhist
## $breaks
## [1] 0 1 2 3 4
##
## $counts
## [1] 1 0 1 1
##
## $density
## [1] 0.3333333 0.0000000 0.3333333 0.3333333
##
## $mids
## [1] 0.5 1.5 2.5 3.5
##
## $xname
## [1] "X"
##
## $equidist
## [1] TRUE
##
## attr(,"class")
## [1] "histogram"
# base x height
base <- 1
height <- Xhist[['density']]
sum(base*height)
## [1] 1
For another example, use the bins \((0,2]\) and \((2,4]\). So the midpoints are \(1\) and \(3\), and the bin half-width is \(1\). Only one observation, \(0.02\), falls in the bin \((0,2]\). The other two observations, \(3\) and \(3.1\), fall into the bin \((2,4]\). The scaling factor is \(\frac{1}{n 2h}=\frac{1}{3\times 2 \times 1}=\frac{1}{6}\). So the first bin has density \(\hat{f}(1)=1\frac{1}{6}=1/6\) and the second bin has density \(\hat{f}(3)=2\frac{1}{6}=2/6\). The area of the first bin’s rectangle is \(2 \times \hat{f}(1)=2/6=1/3\) and the area of the second rectangle is \(2 \times \hat{f}(3)=4/6=2/3\).
Now intuitively work through an example with three bins instead of four. Compute the areas
Code
Xhist <- hist(X, breaks=c(0, 4/3, 8/3, 4), plot=FALSE, freq=FALSE)
base <- 4/3
height <- Xhist[['density']]
sum(base*height)
## [1] 1
# as a default, R uses bins (, ] instead of [, )
# but you can change that with 'right=F'
# hist(X, breaks=c(0, 4/3, 8/3, 4), plot=F, right=F)