Earlier chapters tested hypotheses with resampling. This chapter develops the theoretical counterpart: when the data are well-behaved, the sampling distribution of a \(t\)-statistic is known in advance, so we can test means, medians, and regression slopes with formulas. We then cover the two kinds of testing error and how Bayes’ theorem turns a test result into an updated belief.
Theoretical Distributions
Just as with one sample tests, we can compute standardized differences. The observed difference is converted into a \(t\)-statistic by dividing by an estimated standard error. Note, however, that we have to compute the standard error for the difference statistic, which is a bit more complicated than for a single sample. Under the assumption that both populations are independently distributed, we can analytically derive the sampling distribution for the differences between two groups.
Differences in Means.
To compare two group means, we standardize the observed difference by its estimated standard error.
The two-sample t-statistic divides the observed mean difference by its estimated standard error: \[\hat{t} = \frac{\hat{M}_{Y1} - \hat{M}_{Y2}}{\sqrt{\hat{S}^2_{Y1}/n_1+\hat{S}^2_{Y2}/n_2}},\] where \(\hat{S}^2_{Yg}\) is the sample variance and \(n_g\) is the sample size for group \(g\).
Welch’s t-test modifies the two-sample \(\hat{t}\) above to account for unequal variances or unequal sample sizes. The modifications use the Welch-Satterthwaite approximation.
The two-sample \(\hat{t}\) is useful as the workhorse standardized test statistic for “two means”: dividing by the standard error puts the gap in standard-deviation units, so the same numerator can be large or small in \(\hat{t}\) units depending on \(n_{1}, n_{2}\) and the within-group variances. With normally distributed group means, this statistic follows Student’s t-distribution, so we can read a \(p\)-value from a formula rather than from resampling. When the two groups have unequal variances or sample sizes, a small adjustment to the degrees of freedom keeps the \(t\)-distribution approximation accurate.
Code
# Sample 1 (e.g., males)
n1 <- 100
Y1 <- rnorm(n1, 0, 2)
#hist(Y1, freq=F, main='Sample 1')
# Sample 2 (e.g., females)
n2 <- 80
Y2 <- rnorm(n2, 1, 1)
#hist(Y2, freq=F, main='Sample 2')
t.test(Y1, Y2, var.equal=FALSE)
##
## Welch Two Sample t-test
##
## data: Y1 and Y2
## t = -4.6157, df = 141.12, p-value = 8.723e-06
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -1.520198 -0.608475
## sample estimates:
## mean of x mean of y
## -0.02595525 1.03838126
Welch’s \(t\)-test is useful as the standard default when comparing two means without assuming equal variances, which is the realistic setting in most applied work (two job markets, two policy regimes, two countries). With the variance-and-normality assumptions in place, the test can be conducted entirely with formulas (no bootstrap resampling required).
The Welch-Satterthwaite equation approximates the degrees of freedom when the two groups have unequal variances: \[\begin{eqnarray}
df = \frac{\left(\hat{S}^2_{Y1}/n_1 + \hat{S}^2_{Y2}/n_2\right)^2}{\frac{(\hat{S}^2_{Y1}/n_1)^2}{n_1-1} + \frac{(\hat{S}^2_{Y2}/n_2)^2}{n_2-1}}.
\end{eqnarray}\] For example, suppose both groups have \(n_1=n_2=10\), with sample variances \(\hat{S}^2_{Y1}=4\) and \(\hat{S}^2_{Y2}=1\). Writing \(v_g=\hat{S}^2_{Yg}/n_g\), we have \(v_1=0.4\) and \(v_2=0.1\), so \[\begin{eqnarray}
df = \frac{(0.4+0.1)^2}{0.4^2/9 + 0.1^2/9} = \frac{0.25}{0.17/9} \approx 13.2.
\end{eqnarray}\] This is below the equal-variance value \(n_1+n_2-2=18\): unequal variances cost degrees of freedom, which widens the \(t\)-distribution and makes the test more conservative.
Code
n1 <- 10; n2 <- 10
v1 <- 4/n1
v2 <- 1/n2
(v1 + v2)^2 / (v1^2/(n1-1) + v2^2/(n2-1))
## [1] 13.23529
We can visualize this by simulating many samples under the null (\(\mu_1=\mu_2\)) and comparing the distribution of \(\hat{t}\) with the theoretical \(t\)-distribution.
Code
# Simulate the t-statistic under the null (both groups same mean)
B <- 399
boot_t2 <- vector(length = B)
for (b in seq(B)) {
Y1_b <- rnorm(n1, 0, 2)
Y2_b <- rnorm(n2, 0, 1)
boot_t2[b] <- t.test(Y1_b, Y2_b, var.equal = FALSE)$statistic
}
# Welch-Satterthwaite degrees of freedom
# (use population variances as approximation)
v1 <- 2^2 / n1
v2 <- 1^2 / n2
df_ws <- (v1 + v2)^2 / (v1^2 / (n1 - 1) + v2^2 / (n2 - 1))
# Overlay: simulated histogram vs. theoretical t-distribution
t_range <- range(c(boot_t2, -4, 4))
hist(boot_t2, breaks = 30, freq = FALSE, border = NA,
col = grey(0.5, 0.5),
xlim = t_range,
xlab = expression(hat(t)),
main = NA)
title('Simulated vs. Theoretical Distribution', font.main = 1)
t_grid <- seq(t_range[1], t_range[2], length = 200)
lines(t_grid, dt(t_grid, df = df_ws), lwd = 2)
legend('topright', legend = c('Simulated', paste0('t(', round(df_ws), ')')),
fill = c(grey(0.5, 0.5), NA), border = NA,
lwd = c(NA, 2), lty = c(NA, 1), bty = 'n')
Regression Slope.
The same ideas apply to regression coefficients. Recall that the OLS slope \(\hat{b}_1 = \hat{C}_{XY}/\hat{V}_X\) is a statistic computed from the data. In the Simple Regression chapter, we estimated variability using data-driven methods (jackknife and bootstrap). Under standard assumptions, we can instead derive the sampling distribution analytically: the \(t\)-statistic \[\begin{eqnarray}
\hat{t} = \frac{\hat{b}_1}{\hat{s}_{\hat{b}_1}}
\end{eqnarray}\] follows a \(t\)-distribution with \(n-2\) degrees of freedom, where \(\hat{s}_{\hat{b}_1}\) is the standard error of the slope. This allows us to test \(H_0: \beta_1 = 0\) using math alone.
Code
# USArrests data (same as Simple Regression chapter)
xy <- USArrests[, c('Murder', 'UrbanPop')]
colnames(xy) <- c('y', 'x')
reg <- lm(y ~ x, data = xy)
# The summary reports theoretical t-statistics and p-values
summary(reg)$coefficients
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.41594246 2.90669257 2.2073000 0.03210725
## x 0.02093466 0.04332647 0.4831841 0.63116178
Manual verification of the theoretical \(t\)-statistic for the slope:
Code
n <- nrow(xy)
b1 <- coef(reg)[2]
e <- resid(reg)
s_e <- sqrt(sum(e^2) / (n - 2)) # residual standard error
s_b1 <- s_e / sqrt(sum((xy[, 'x'] - mean(xy[, 'x']))^2)) # SE of slope
t_stat <- b1 / s_b1
# Compare with summary output
c(manual = t_stat, summary = summary(reg)$coefficients[2, 3])
## manual.x summary
## 0.4831841 0.4831841
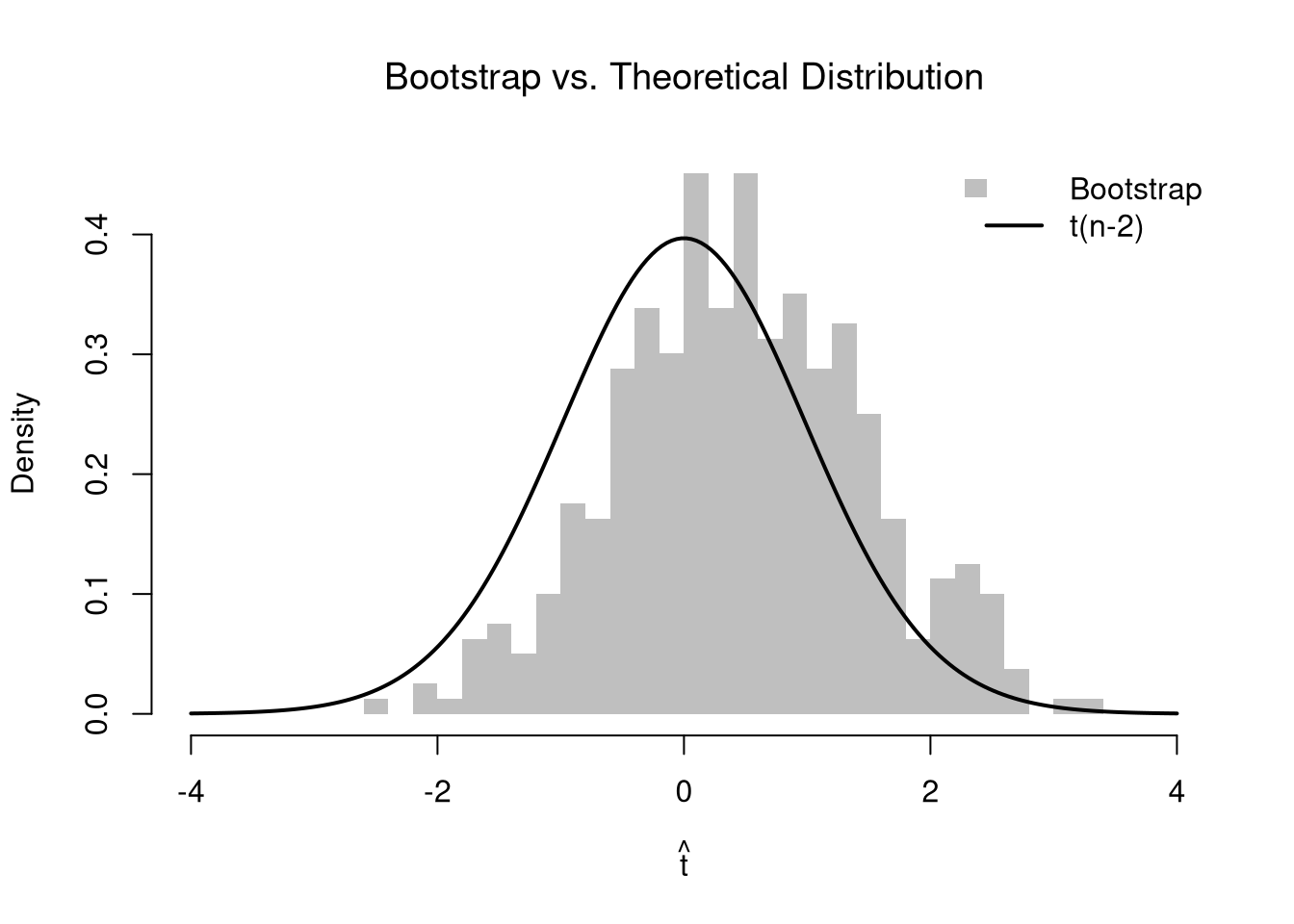
We can compare the bootstrap sampling distribution of \(\hat{t}\) (histogram) with the theoretical \(t_{n-2}\) distribution (curve). They should be similar, but are not identical because the theoretical result assumes normally distributed errors.
Code
# Bootstrap distribution of the t-statistic
n <- nrow(xy)
B <- 399
boot_t <- vector(length = B)
for (b in seq(B)) {
b_id <- sample(nrow(xy), replace = TRUE)
xy_b <- xy[b_id, ]
reg_b <- lm(y ~ x, data = xy_b)
# Use theoretical SE from summary
boot_t[b] <- summary(reg_b)$coefficients[2, 3]
}
# Overlay: bootstrap histogram vs. theoretical t-distribution
t_range <- range(c(boot_t, -4, 4))
hist(boot_t, breaks = 30, freq = FALSE, border = NA,
col = grey(0.5, 0.5),
xlim = t_range,
xlab = expression(hat(t)),
main = NA)
title('Bootstrap vs. Theoretical Distribution', font.main = 1)
# Theoretical t(n-2) density
t_grid <- seq(t_range[1], t_range[2], length = 200)
lines(t_grid, dt(t_grid, df = n - 2), lwd = 2)
legend('topright', legend = c('Bootstrap', 't(n-2)'),
fill = c(grey(0.5, 0.5), NA), border = NA,
lwd = c(NA, 2), lty = c(NA, 1), bty = 'n')
We can compute the \(p\)-value for \(H_0: \beta_1 = 0\) two ways: from the theoretical \(t\)-distribution and from the bootstrap distribution. Both ask how extreme the observed \(\hat{t}\) is under the null.
Code
t_obs <- summary(reg)$coefficients[2, 3]
# Theoretical p-value: Prob(|t| >= |t_obs|) under t(n-2)
p_theory <- 2 * pt(-abs(t_obs), df = n - 2)
# Bootstrap p-value: fraction of bootstrap |t|'s >= |t_obs|
p_boot <- mean(abs(boot_t) >= abs(t_obs))
c(theoretical = p_theory, bootstrap = p_boot)
## theoretical bootstrap
## 0.6311618 0.6516291
Type II Errors
A hypothesis test starts with a null \(H_0\) and an alternative \(H_A\), and produces a decision (reject or fail-to-reject) from finite sample data. Because the data have variability, the decision can be wrong in two ways.
A Type I error is rejecting \(H_{0}\) when \(H_{0}\) is true (a false positive). A Type II error is failing to reject \(H_{0}\) when \(H_{0}\) is false (a false negative).
This distinction is useful because the two error types are managed by different levers: we control Type I error by setting the significance level \(\alpha=Prob(\text{Type I})\) before looking at the data, while Type II error is harder to control directly and depends on the sample size and the true effect size. Reducing one error rate usually raises the other for a fixed sample.
| \(H_0\) is True |
Correct (no detection) |
Type I Error (False Positive) |
| \(H_0\) is False |
Type II Error (False Negative; missed detection) |
Correct (effect detected) |
Here is a Courtroom example: Someone suspected of committing a crime is at trial, and they are either guilty or not (a Bernoulli random variable). You hypothesize that the suspect is innocent, and a jury can either convict them (decide guilty) or free them (decide not-guilty). Recall that fail-to-reject a hypothesis does not mean accepting it, so deciding not-guilty does not necessarily mean innocent.
| Suspect Innocent |
Correctly Freed |
Falsely Convicted |
| Suspect Guilty |
Falsely Freed |
Correctly Convicted |
Statistical Power.
The complement of Type II error has its own name because it is what we actually want from the test.
Statistical power \(1-\beta\) is the probability of correctly rejecting \(H_{0}\) when \(H_{0}\) is false: \[\text{Power} = 1 - \beta = 1 - Prob(\text{Type II Error}).\] (Here \(\beta\) is the Type II error probability, not the regression coefficient \(\beta_{1}\) from Bivariate Probability.)
Power is useful as the probability that a true effect of a given size will actually show up as a rejection in our data: it rises with the sample size \(n\), the true effect size, and the significance level \(\alpha\). The complementary error rate, the significance level \(\alpha = Prob(\text{Type I Error})\), is something we choose in advance (commonly \(\alpha=0.05\)). Power is less often chosen directly; it follows from the chosen sample size and the assumed effect size, and lets us judge whether a study is well-powered to detect what we care about.
The code below runs a small simulation using a shifted, nonparametric bootstrap. Two-sided test; studentized statistic, for \(H0: \mu = 0\)
Code
# Power for Two-sided test;
# nonparametric bootstrap, studentized statistic
n <- 25
mu <- 0
alpha <- 0.05
B <- 299
sim_reps <- 100
p_values <- rep(NA, sim_reps)
for (i in seq(p_values)) {
# Generate data
X <- rnorm(n, mean=0.2, sd=1)
# Observed statistic
X_bar <- mean(X)
T_obs <- (X_bar - mu) / (sd(X)/ sqrt(n)) ##studentized
# Bootstrap null distribution of the statistic
T_boot <- rep(NA, B)
X_null <- X - X_bar + mu # Impose the null by recentering
for (b in seq(T_boot)) {
X_b <- sample(X_null, size = n, replace = TRUE)
T_b <- (mean(X_b) - mu) / (sd(X_b)/sqrt(n))
T_boot[b] <- T_b
}
# Two-sided bootstrap p-value
pval <- mean(abs(T_boot) >= abs(T_obs))
p_values[i] <- pval
}
power <- mean(p_values < alpha)
power
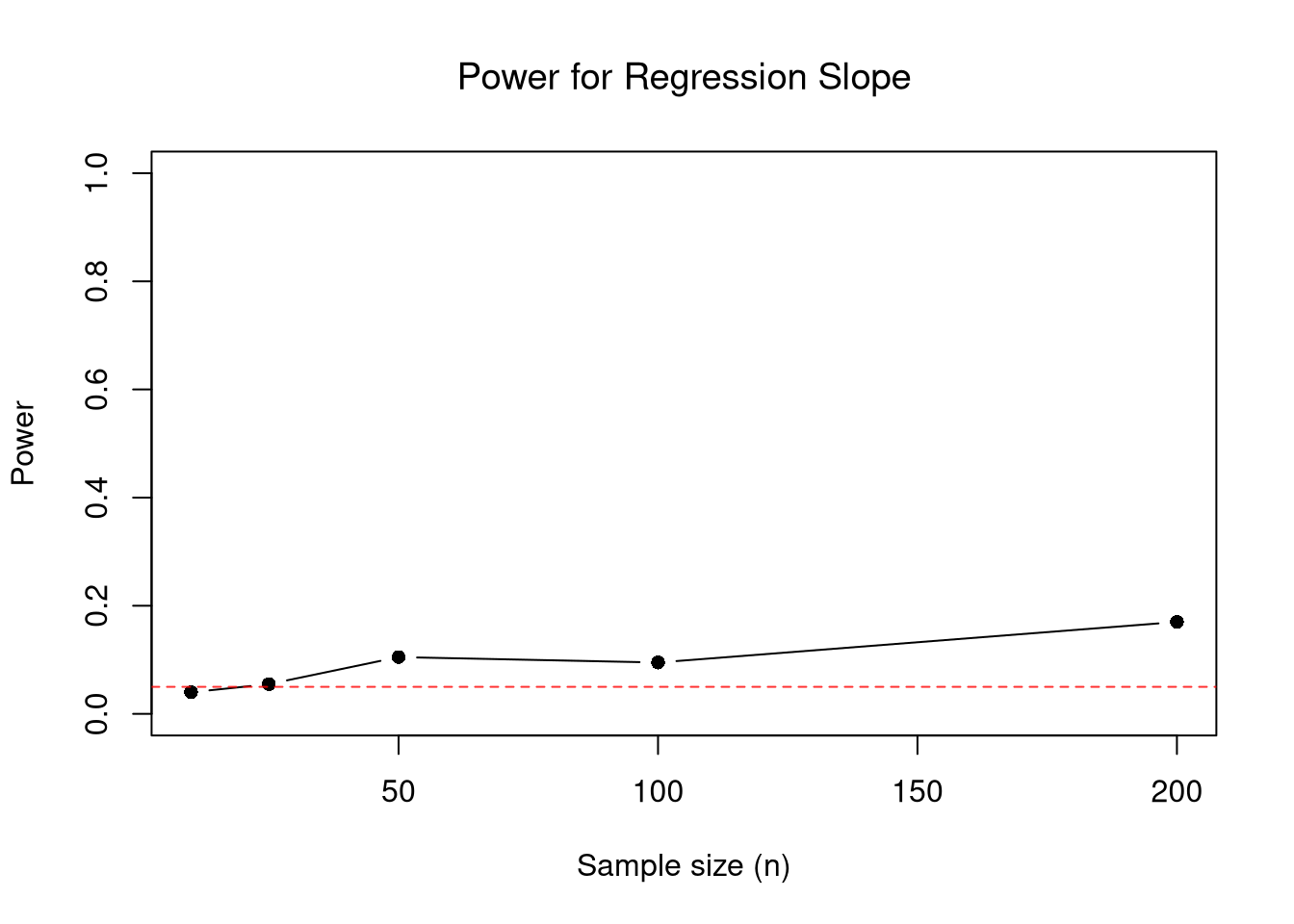
There is an important Trade-off for fixed sample sizes: Increasing significance (fewer false positive) often lowers power (more false negatives). Generally, power depends on the effect size and sample size: bigger true effects and larger \(n\) make it easier to detect real differences (higher power, lower \(\beta\)).
Regression Slope Example.
Continuing the USArrests regression, consider testing \(H_0: \beta_1 = 0\). We can simulate Type I and Type II error rates by generating data that resemble the original. When the true slope is \(0\) (null is true), rejecting is a Type I Error. When the true slope is nonzero (null is false), failing to reject is a Type II Error.
Code
# DGP calibrated to USArrests regression
beta0 <- coef(reg)[1]
beta1_true <- coef(reg)[2]
sigma_e <- summary(reg)$sigma
x_mean <- mean(xy[, 'x'])
x_sd <- sd(xy[, 'x'])
# Function: simulate data, return theoretical p-value for slope
sim_pval <- function(n, beta1) {
X <- rnorm(n, mean = x_mean, sd = x_sd)
Y <- beta0 + beta1 * X + rnorm(n, 0, sigma_e)
summary(lm(Y ~ X))$coefficients[2, 4]
}
sim_reps <- 200
alpha <- 0.05
# Type I Error rate: true slope = 0
pvals_null <- replicate(sim_reps, sim_pval(n = 50, beta1 = 0))
type1_rate <- mean(pvals_null < alpha)
type1_rate # should be close to alpha
## [1] 0.055
# Power: true slope = beta1_true
pvals_alt <- replicate(sim_reps, sim_pval(n = 50, beta1 = beta1_true))
power_est <- mean(pvals_alt < alpha)
power_est
## [1] 0.09
Code
# Power increases with sample size
n_grid <- c(10, 25, 50, 100, 200)
power_by_n <- sapply(n_grid, function(ni) {
pvals <- replicate(sim_reps, sim_pval(ni, beta1 = beta1_true))
mean(pvals < alpha)
})
plot(n_grid, power_by_n, type = 'b', pch = 16,
xlab = 'Sample size (n)', ylab = 'Power',
ylim = c(0, 1),
main = NA)
title('Power for Regression Slope', font.main = 1)
abline(h = alpha, lty = 2, col = rgb(1, 0, 0, .8))
Bayesian Updating
Bayes’ Theorem.
Bayes’ theorem flips the direction of conditioning, which is exactly how an observation updates a prior belief.
Bayes’ theorem relates the two conditional directions: \[Prob(X_i=x \mid Y_i=y) = \frac{Prob(Y_i=y \mid X_i=x)\,Prob(X_i=x)}{Prob(Y_i=y)}.\]
Bayes’ theorem is useful as the mechanism by which an observation \(Y_{i}=y\) updates a prior belief about \(X_{i}\) into a posterior belief:
- \(Prob(X_i=x)\) is the prior probability for \(X_i=x\).
- \(Prob(Y_i=y|X_i=x)\) is the likelihood of seeing \(Y_i=y\) if \(X_i=x\) is true.
- \(Prob(X_i=x|Y_i=y)\) is the posterior, your updated probability after seeing \(Y_i=y\).
A useful way to remember the structure is “Posterior \(\propto\) Likelihood \(\times\) Prior”. For two states, the posterior odds equal the prior odds times a likelihood ratio.
Building on the coin-flip examples from the previous chapter, suppose we observe the outcome of the second coin (\(Y_i\)) and want to update our belief about the first coin (\(X_i\)).
Fair coins. With \(Prob(X_i=x,Y_i=y)=1/4\) for all \(x,y\in\{0,1\}\), the prior is \(Prob(X_i=1)=1/2\) and the likelihoods are \[\begin{eqnarray}
Prob(Y_i=1|X_i=1)=1/2,\quad Prob(Y_i=1|X_i=0)=1/2.
\end{eqnarray}\] Applying Bayes’ theorem, \[\begin{eqnarray}
Prob(X_i=1|Y_i=1)
&=& \frac{Prob(Y_i=1|X_i=1)Prob(X_i=1)}{Prob(Y_i=1)}
= \frac{(1/2)(1/2)}{1/2} = \frac{1}{2}.
\end{eqnarray}\] The posterior equals the prior because the coins are independent, so seeing one coin tells you nothing about the other.
Code
# Fair coins
probs <- c(0.25, 0.25, 0.25, 0.25)
P_xy <- matrix(probs, nrow = 2,
dimnames = list(c('Y=0', 'Y=1'), c('X=0', 'X=1')))
# Marginals
P_x <- colSums(P_xy)
P_y <- rowSums(P_xy)
# Likelihood: Prob(Y=1 | X=x)
PY1_x <- P_xy['Y=1', ] / P_x
PY1_x
## X=0 X=1
## 0.5 0.5
# Posterior: Prob(X=1 | Y=1)
posterior_x1 <- (PY1_x['X=1'] * P_x['X=1']) / P_y['Y=1']
posterior_x1 # equals the prior
## X=1
## 0.5
Are the coins statistically independent?
Unfair coins. Now consider the joint distribution from the previous chapter with probs <- c(0.4, 0.2, 0.1, 0.3):
| \(y=0\) |
\(0.4\) |
\(0.1\) |
\(0.5\) |
| \(y=1\) |
\(0.2\) |
\(0.3\) |
\(0.5\) |
| Marginal |
\(0.6\) |
\(0.4\) |
\(1\) |
The prior is \(Prob(X_i=1)=0.4\). The likelihoods are \[\begin{eqnarray}
Prob(Y_i=1|X_i=1) = \frac{0.3}{0.4} = 0.75,\quad
Prob(Y_i=1|X_i=0) = \frac{0.2}{0.6} = \frac{1}{3}.
\end{eqnarray}\] Applying Bayes’ theorem, \[\begin{eqnarray}
Prob(X_i=1|Y_i=1)
&=& \frac{0.75 \times 0.4}{0.75 \times 0.4 + \frac{1}{3}\times 0.6}
= \frac{0.3}{0.3+0.2} = 0.6.
\end{eqnarray}\] The prior probability of heads on the first coin was \(0.4\), but after seeing heads on the second coin, it increases to \(0.6\). The coins are not independent: when the second coin shows heads, it is more likely that the first coin also shows heads.
Code
# Unfair coins
probs <- c(0.4, 0.2, 0.1, 0.3)
P_xy <- matrix(probs, nrow = 2,
dimnames = list(c('Y=0', 'Y=1'), c('X=0', 'X=1')))
P_xy
## X=0 X=1
## Y=0 0.4 0.1
## Y=1 0.2 0.3
# Marginals
P_x <- colSums(P_xy)
P_y <- rowSums(P_xy)
# Likelihood: Prob(Y=1 | X=x)
PY1_x <- P_xy['Y=1', ] / P_x
PY1_x
## X=0 X=1
## 0.3333333 0.7500000
# Posterior: Prob(X=1 | Y=1)
posterior_x1 <- (PY1_x['X=1'] * P_x['X=1']) / P_y['Y=1']
posterior_x1 # prior was 0.4, posterior is 0.6
## X=1
## 0.6
# Also compute Prob(X=1 | Y=0)
PY0_x <- P_xy['Y=0', ] / P_x
posterior_x1_y0 <- (PY0_x['X=1'] * P_x['X=1']) / P_y['Y=0']
posterior_x1_y0 # seeing tails lowers belief to 0.2
## X=1
## 0.2
Are the coins statistically independent?
Bayesian Screening.
A common application of Bayes’ theorem is interpreting a positive result from a diagnostic test.
For a binary screening test where \(X_{i}=1\) means “condition present” and \(Y_{i}=1\) means “test positive”:
Prevalence \(Prob(X_{i}=1)\) is the base rate of the condition in the population.
Sensitivity \(Prob(Y_{i}=1\mid X_{i}=1)\) is the probability of a positive result when the condition is present.
False positive rate \(Prob(Y_{i}=1\mid X_{i}=0)\) is the probability of a positive result when it is absent.
Screening is useful for converting test accuracy and base rates into the quantity an individual actually cares about: the posterior \(Prob(X_{i}=1\mid Y_{i}=1)\), the probability of having the condition given a positive result. The three inputs play different roles: sensitivity and the false positive rate describe the test, while prevalence describes the population. Suppose a screening test has sensitivity \(0.90\), false positive rate \(0.08\), and prevalence \(0.12\). Applying Bayes’ theorem, \[\begin{eqnarray}
Prob(X_i=1|Y_i=1)
&=&
\frac{0.90\times0.12}{0.90\times0.12 + 0.08\times0.88}
\approx 0.605.
\end{eqnarray}\] Even with a good test, the posterior depends strongly on prevalence: rare conditions produce many false alarms even when the test is accurate.
Code
# States: X in {0, 1}, signal Y in {0, 1}
# Prior Prob(X_i=1)
p_x1 <- 0.12
# Test characteristics
p_y1_x1 <- 0.90
p_y1_x0 <- 0.08
# Law of total probability for Prob(Y_i=1)
p_y1 <- p_y1_x1 * p_x1 + p_y1_x0 * (1 - p_x1)
# Bayes posterior Prob(X_i=1 | Y_i=1)
p_x1_y1 <- (p_y1_x1 * p_x1) / p_y1
p_x1_y1
## [1] 0.6053812
# Also compute Prob(X_i=1 | Y_i=0)
p_y0_x1 <- 1 - p_y1_x1
p_y0_x0 <- 1 - p_y1_x0
p_y0 <- p_y0_x1 * p_x1 + p_y0_x0 * (1 - p_x1)
p_x1_y0 <- (p_y0_x1 * p_x1) / p_y0
p_x1_y0
## [1] 0.01460565
Regression Slope Example.
The screening test has the same structure as testing a regression slope. Let \(X_i=1\) mean “slope is truly nonzero” and \(Y_i=1\) mean “the test rejects \(H_0\).” Then sensitivity equals power, the false positive rate equals \(\alpha\), and prevalence is your prior belief that the slope is nonzero. Using the simulation results from the previous section:
Code
# Prior: 50-50 chance the slope is nonzero
prior_nonzero <- 0.5
# 'Sensitivity' = power, 'False positive rate' = alpha
p_reject <- power_est * prior_nonzero + alpha * (1 - prior_nonzero)
# Posterior: Prob(slope nonzero | test rejects)
post_nonzero <- (power_est * prior_nonzero) / p_reject
post_nonzero
## [1] 0.6428571
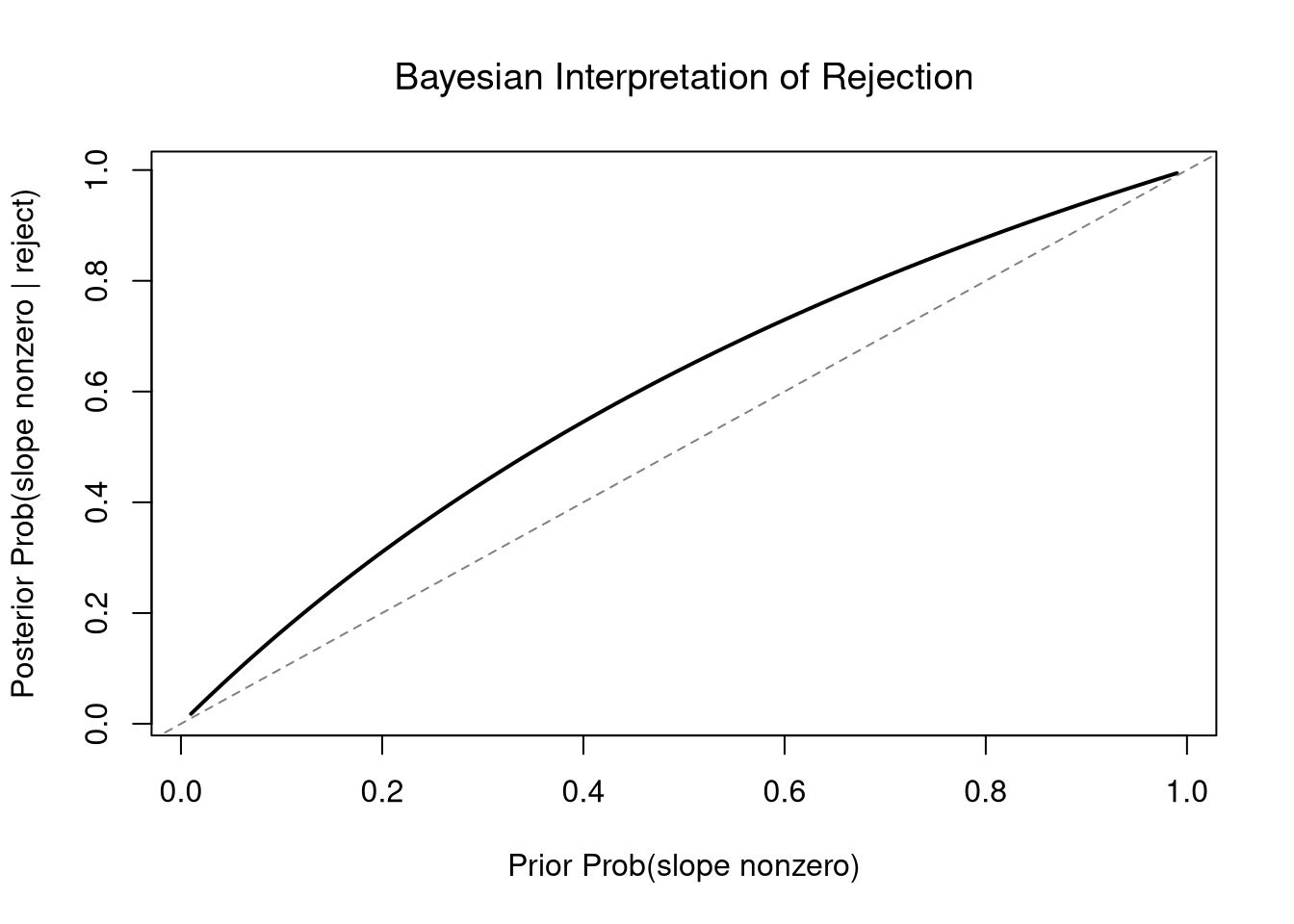
Even with moderate power, a rejection substantially updates the posterior probability that the slope is nonzero. A weaker prior (e.g., \(Prob(\beta_1 \neq 0) = 0.1\)) would require stronger evidence to reach the same posterior.
Code
# How the posterior changes with different priors
prior_grid <- seq(0.01, 0.99, by = 0.01)
post_grid <- (power_est * prior_grid) /
(power_est * prior_grid + alpha * (1 - prior_grid))
plot(prior_grid, post_grid, type = 'l', lwd = 2,
xlab = 'Prior Prob(slope nonzero)',
ylab = 'Posterior Prob(slope nonzero | reject)',
main = NA)
title('Bayesian Interpretation of Rejection', font.main = 1)
abline(0, 1, lty = 2, col = grey(0.5))
Exercises
Comment the script you wrote for this chapter, then restart R and check that it runs from a clean session, then check the script with AI as explained in Working with AI. Write three sentences from memory on the main statistical idea of this chapter, and ask the assistant what is wrong, vague, or missing. Finish with your own questions about whatever you found hardest.
Explain the difference between a Type I Error and a Type II Error in the context of testing \(H_0: \beta_1 = 0\) for a regression slope. Why does increasing the sample size \(n\) improve power without changing the significance level \(\alpha\)?
A screening test has sensitivity \(Prob(Y_i=1|X_i=1) = 0.95\), false positive rate \(Prob(Y_i=1|X_i=0) = 0.10\), and prevalence \(Prob(X_i=1) = 0.05\). Use Bayes’ theorem to compute the posterior probability \(Prob(X_i=1|Y_i=1)\). Explain why the posterior is much lower than the sensitivity.
Using the USArrests dataset, regress Murder on UrbanPop with lm. Extract the theoretical \(t\)-statistic and \(p\)-value for the slope from summary(). Then write a bootstrap loop with \(B = 399\) replicates to compute a bootstrap \(p\)-value and compare it to the theoretical one.
Further Reading.
Many introductory econometrics textbooks have a good appendix on probability and statistics. See also the further reading in Bivariate Probability.
Recall
This chapter built theoretical tests on top of the population objects from the previous chapter: Welch’s \(t\)-test for two means, the theoretical \(t_{n-2}\) distribution for a regression slope, the Type I / Type II error distinction with statistical power, and Bayes’ theorem for converting a test rejection into a posterior. The USArrests slope simulation showed both ideas concretely: the bootstrap histogram of \(\hat{t}\) matched the theoretical \(t_{n-2}\) density, and the same regression was used to estimate power across sample sizes \(n \in \{10, 25, 50, 100, 200\}\). The next chapter closes Part 2 by turning to communication: interactive figures and tables, polishing, and Quarto reports.
McGill, Robert, John W. Tukey, and Wayne A. Larsen. 1978.
“Variations of Box Plots.” The American Statistician 32 (1): 12–16.
https://doi.org/10.1080/00031305.1978.10479236.