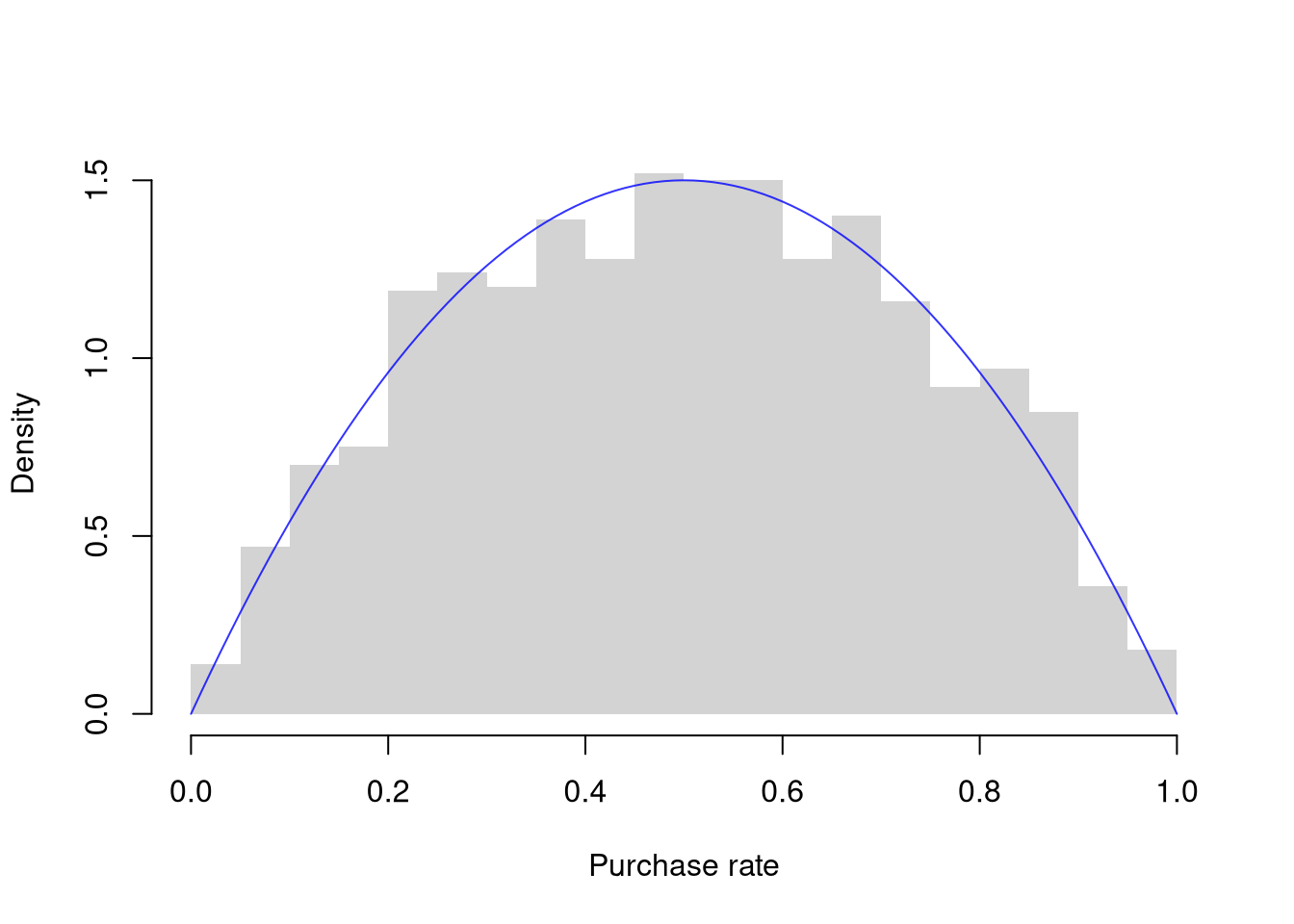
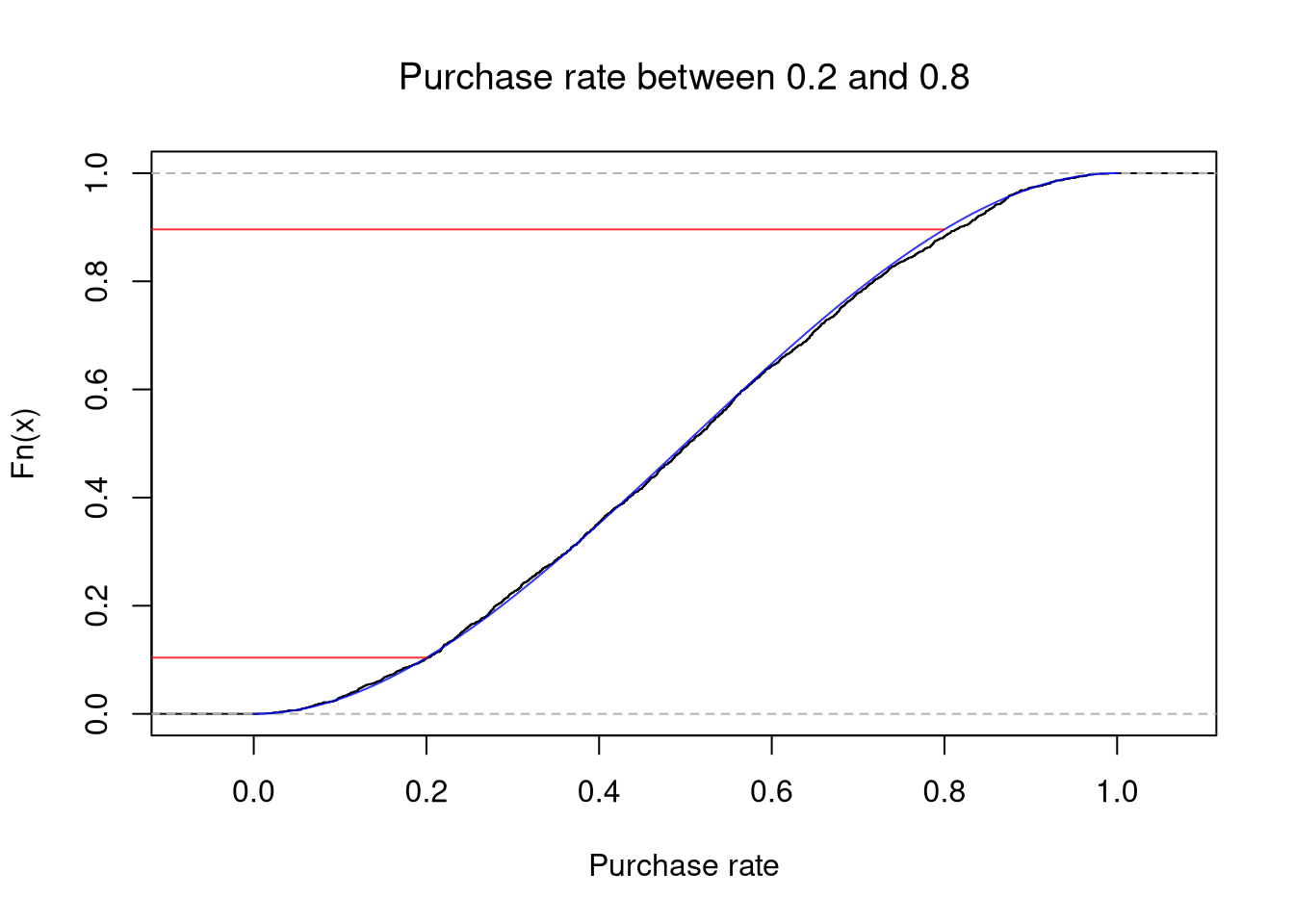
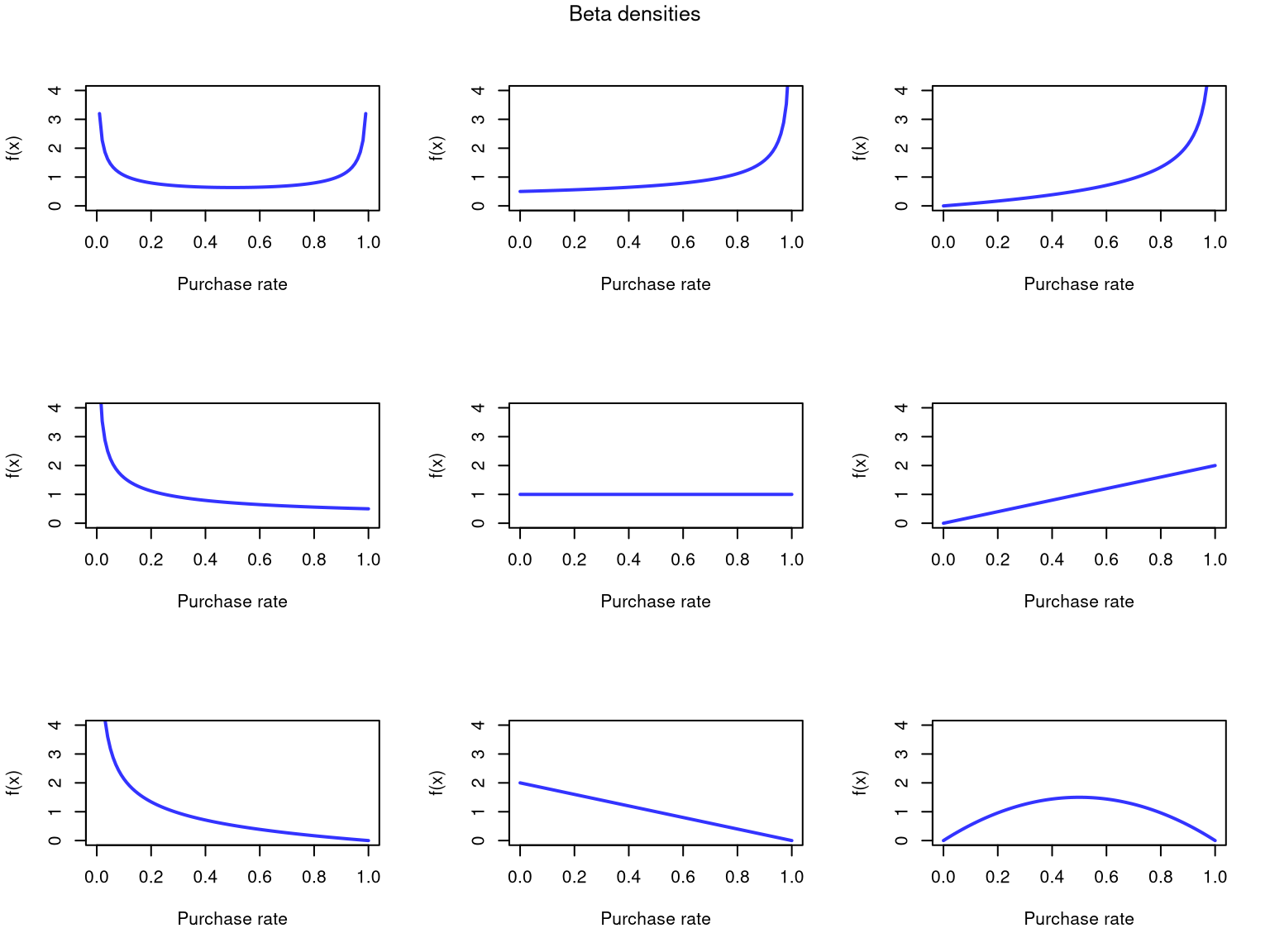
Binomial.
A single Bernoulli trial gives a \(0\) or a \(1\); counting how many successes occur across \(n\) such trials is the next-most-common discrete distribution.
A Binomial random variable counts the number of successes in \(n\) independent Bernoulli trials, each with success probability \(p\). Its PMF is \(Prob(X_{i} = x) = \binom{n}{x} p^{x} (1-p)^{n-x}\) for \(x \in \{0, 1, \ldots, n\}\), mean \(np\), and variance \(np(1-p)\).
The Binomial distribution is useful for any situation that aggregates independent yes/no events: defective items in a batch, customers who enter a store, voters who pick a candidate, free throws that go in. The full specification gathers sample space, PMF, and CDF in one place: \[\begin{eqnarray}
X_{i} \in \{0,1,\ldots,n\} \\
Prob(X_{i}=x) &=& \binom{n}{x}p^{x}(1-p)^{n-x} \\
F(x) = Prob(X_{i} \leq x) &=& \sum_{k=0}^{\lfloor x \rfloor} Prob(X_{i}=x)
\end{eqnarray}\]
The simplest case: how many heads will I get when I flip a fair coin twice? We can first see that there are four potential outcomes: \(\{ (1,1), (1,0), (0,1), (0,0) \}\), each of which are equally likely. The corresponding sums of \(\{2,1,1,0\}\) are equally likely, which leads to probabilities \(Prob(X_{i}=0)=1/4\), \(Prob(X_{i}=1)=2/4\), and \(Prob(X_{i}=2)=1/4\).
If the coin is unfair, with probability of heads equal to \(0.25\), then the four outcomes \(\{(1,1), (1,0), (0,1), (0,0)\}\) are no longer equally likely: they have probabilities \(\{0.0625, 0.1875, 0.1875, 0.5625\}\). Collecting the matching sums, \(Prob(X_{i}=2)=0.0625\), \(Prob(X_{i}=1)=0.1875+0.1875=0.375\), and \(Prob(X_{i}=0)=0.5625\).
When I flip a coin three times, the potential outcomes are \[\begin{eqnarray}
\{
(1,1,1), (1,1,0), (1,0,1), (1,0,0),\\
(0,1,1), (0,1,0), (0,0,1), (0,0,0)
\}
\end{eqnarray}\] Assuming the coin is fair, compute the probabilities for each possible sum. Assuming the coin is unfair, with probability of heads equal to \(0.25\), compute the probabilities for each possible sum.
In general, we use the Binomial distribution. The \(\binom{n}{x}\) term is called the binomial coefficient and it counts all the different groups that lead to the same sum. The other terms intuitively reflect the probabilities of getting \(x\) successes and \(n-x\) failures.
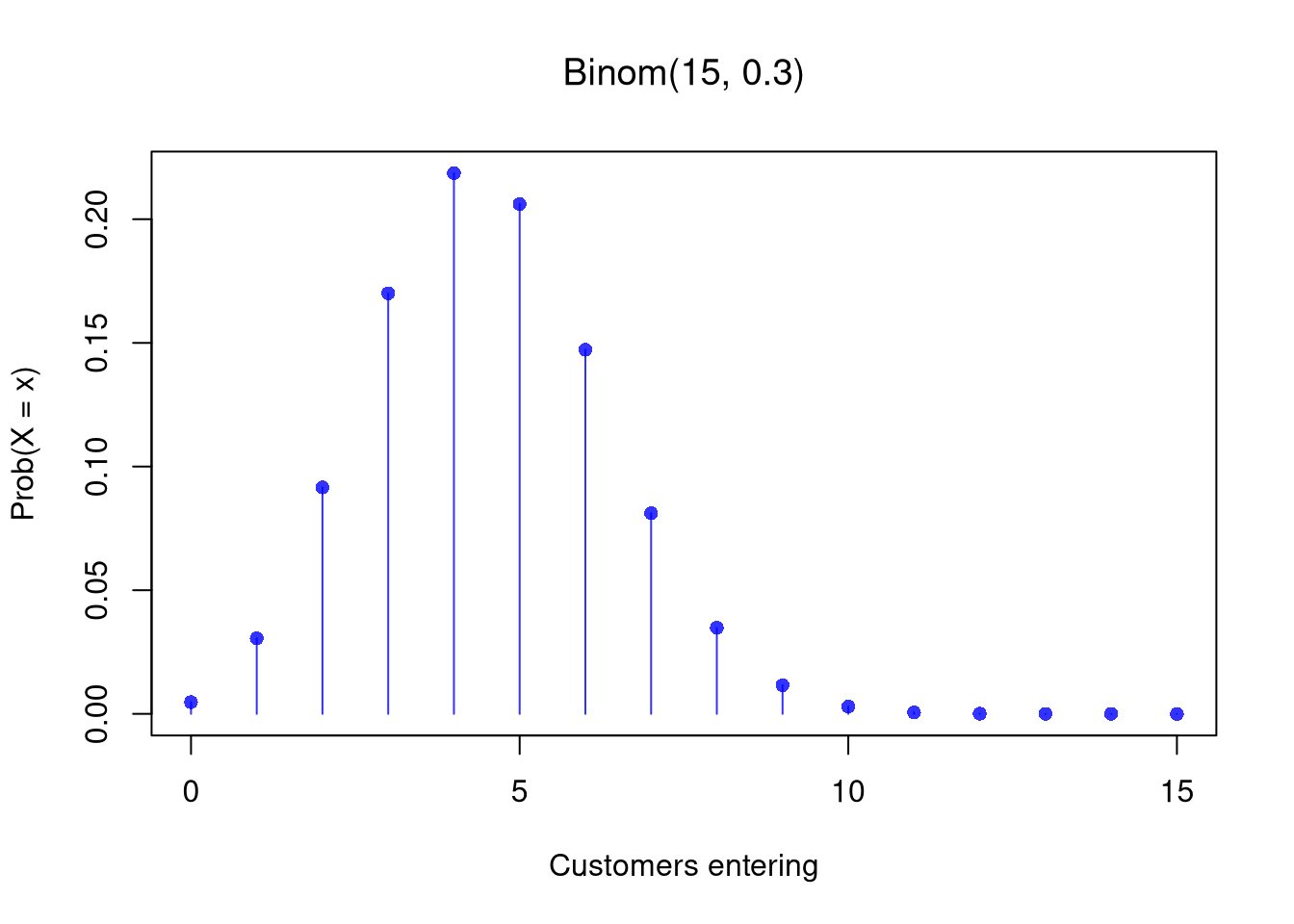
For example, suppose \(n=15\) people walk past a store each hour and each has a \(p=30\%\) chance of entering. The number of customers who enter is \(X_{i} \sim \text{Binom}(15, 0.3)\).
Code
## Store: 15 passers-by, 30% chance each enters
n <- 15
p <- 0.3
# PMF plot
x <- seq(0, n)
f_x <- dbinom(x, n, p)
plot(x, f_x, type = 'h', col = rgb(0, 0, 1, .8),
main=NA, xlab = 'Customers entering', ylab = 'Prob(X = x)')
title(bquote(paste('Binom(', .(n), ', ', .(p), ')')), font.main=1)
points(x, f_x, pch = 16, col = rgb(0, 0, 1, .8))
Code
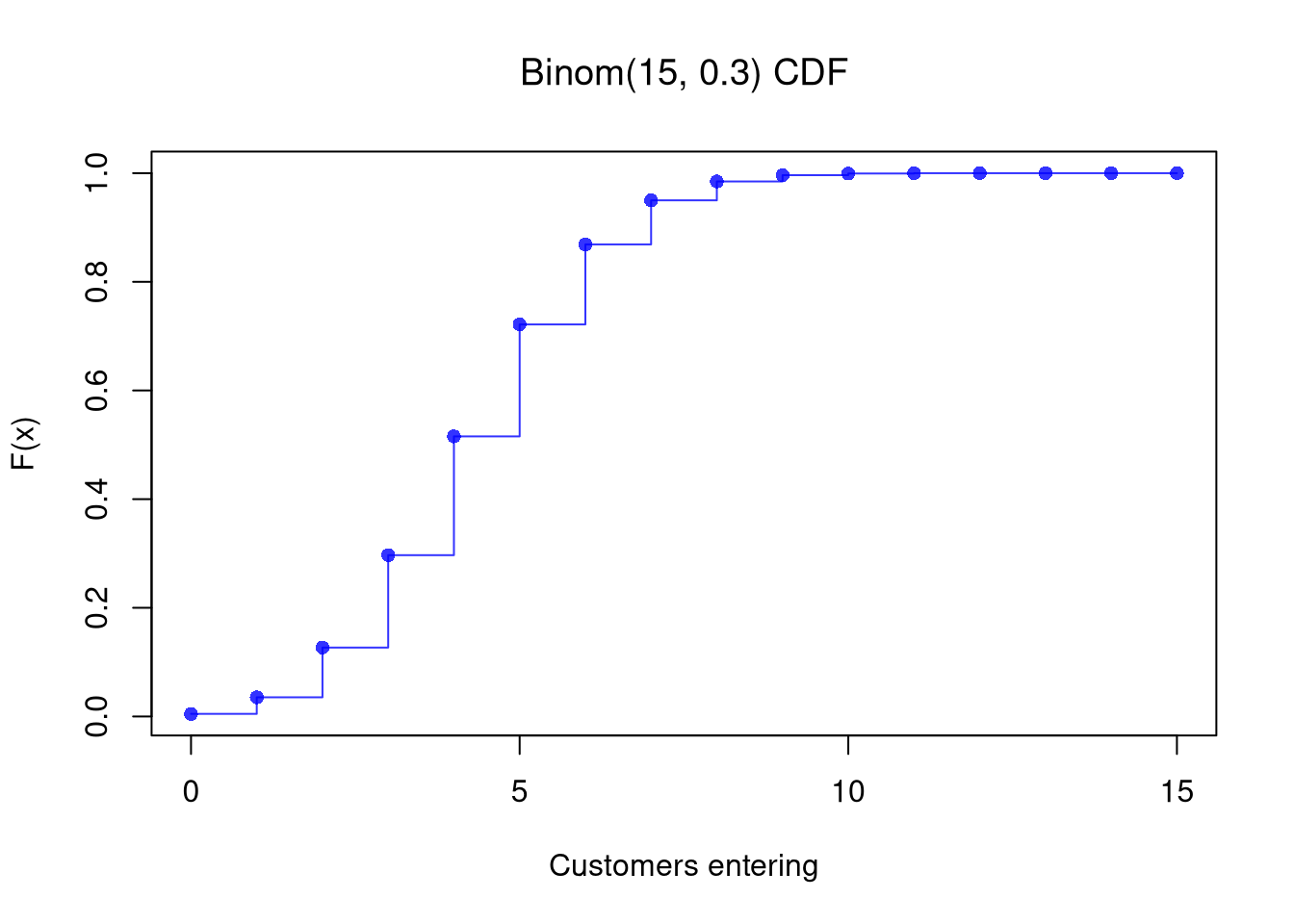
## Theoretical CDF
F_x <- pbinom(x, n, p)
plot(x, F_x, type='s', col=rgb(0, 0, 1, .8),
xlab = 'Customers entering', ylab = 'F(x)', main=NA)
points(x, F_x, pch=16, col=rgb(0, 0, 1, .8))
title(bquote(paste('Binom(', .(n), ', ', .(p), ') CDF')), font.main=1)
A quality inspector checks \(n=20\) items from a production line with a \(5\%\) defect rate (\(p=0.05\)). What is the probability of finding \(2\) or fewer defectives?
We need \(Prob(X_{i} \leq 2) = F(2)\) where \(X_{i} \sim \text{Binom}(20, 0.05)\). By hand, the first few terms are \[\begin{eqnarray}
Prob(X_{i}=0) &=& \binom{20}{0}(0.05)^{0}(0.95)^{20} \approx 0.36 \\
Prob(X_{i}=1) &=& \binom{20}{1}(0.05)^{1}(0.95)^{19} \approx 0.38 \\
Prob(X_{i}=2) &=& \binom{20}{2}(0.05)^{2}(0.95)^{18} \approx 0.19
\end{eqnarray}\] So \(Prob(X_{i} \leq 2) \approx 0.36 + 0.38 + 0.19 = 0.93\). There is roughly a \(93\%\) chance the inspector finds \(2\) or fewer defectives.
Code
# Individual terms
x <- c(0, 1, 2)
px <- dbinom(x, size=20, prob=0.05)
round(px, 2)
## [1] 0.36 0.38 0.19
# CDF: Prob(X <= 2)
pbinom(2, size=20, prob=0.05)
## [1] 0.9245163
Suppose that employees at a company are \(70%\) female and \(30%\) male. If we select a random sample of eight employees, what is the probability that \(2\) in the sample are female? That \(\geq 2\) are female?
Try conducting a simulation first,
Code
n <- 8
p <- 0.3
X <- rbinom(1000, n, p)
For \(n\) coin flips, show that \(\mathbb{E}[X_{i}]=np\) and \(\mathbb{V}[X_{i}]=np(1-p)\). Build on the case \(n=2\) above, then consider case \(n=3\), and then the general case of any \(n\).
Code
# Compare empirical simulation vs theoretical
n <- 2
p <- 3/4
X <- rbinom(1000, size=n, prob=p)
# Mean
c(empirical = mean(X), theoretical = n*p)
## empirical theoretical
## 1.506 1.500
# Variance
c(empirical = var(X), theoretical = n*p*(1-p))
## empirical theoretical
## 0.3783423 0.3750000
Poisson.
When the trials are too many and individually too rare to count, the Binomial limits to a simpler model parameterized by a single rate.
A Poisson random variable counts events in a fixed interval when events are rare, independent, and arrive at a constant rate \(\lambda\). Its PMF is \(Prob(X_{i} = x) = e^{-\lambda} \lambda^{x} / x!\) for \(x \in \{0, 1, 2, \ldots\}\), and the mean and variance are both \(\lambda\).
The Poisson distribution is useful for count outcomes where events are sparse but the opportunities are many: arrivals at a store, decay events from a radioactive source, typos per page. The single parameter \(\lambda\) is the average number of events per interval, and the full specification adds the CDF: \[\begin{eqnarray}
X_{i} \in \{0,1,\ldots\} \\
Prob(X_{i}=x) &=& e^{-\lambda}\lambda^x/x! \\
F(x) = Prob(X_{i} \leq x) &=& \sum_{k=0}^{\lfloor x \rfloor} Prob(X_{i}=x)
\end{eqnarray}\] Note the infinite discrete support \(\{0,1,2,\ldots\}\): there is no upper bound on the count, though large values become vanishingly unlikely.
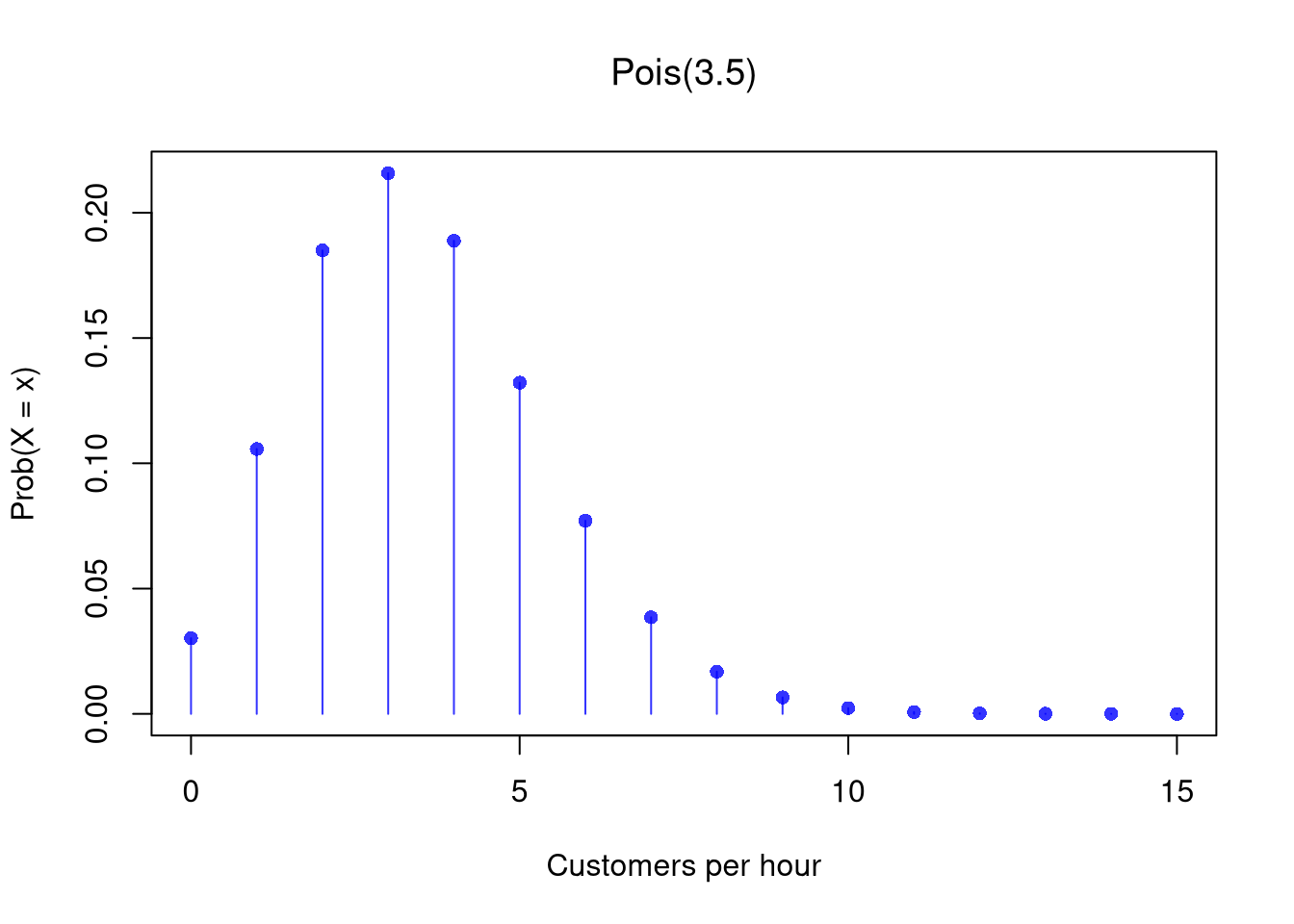
For example, a small store averages \(\lambda = 3.5\) customers per hour. In any given hour the actual count might be 2, or 5, or 7. For our store, \(\lambda = 3.5\) means we expect 3.5 customers per hour on average and the following assumptions hold
- Arrivals are independent of each other (one customer entering does not make the next more or less likely)
- The average rate \(\lambda\) is constant over the interval
- Two customers cannot arrive at exactly the same instant
We can then compute a few probabilities by hand. For example, the chance that zero customers arrive in a given hour is \[\begin{eqnarray}
Prob(X_{i}=0) &=& e^{-3.5} \cdot 3.5^{0} / 0! = e^{-3.5} \approx 0.030
\end{eqnarray}\] The chance of exactly 2 customers is \[\begin{eqnarray}
Prob(X_{i}=2) &=& e^{-3.5} \cdot 3.5^{2} / 2! = e^{-3.5} \cdot 6.125 \approx 0.185
\end{eqnarray}\]
Code
## Store: lambda = 3.5 customers per hour
lambda <- 3.5
# PMF plot
x <- seq(0, 15)
f_x <- dpois(x, lambda)
plot(x, f_x, type='h', col=rgb(0, 0, 1, .8),
xlab = 'Customers per hour', ylab = 'Prob(X = x)', main=NA)
points(x, f_x, pch = 16, col = rgb(0, 0, 1, .8))
title(bquote(paste('Pois(', .(lambda), ')')), font.main=1)
Code
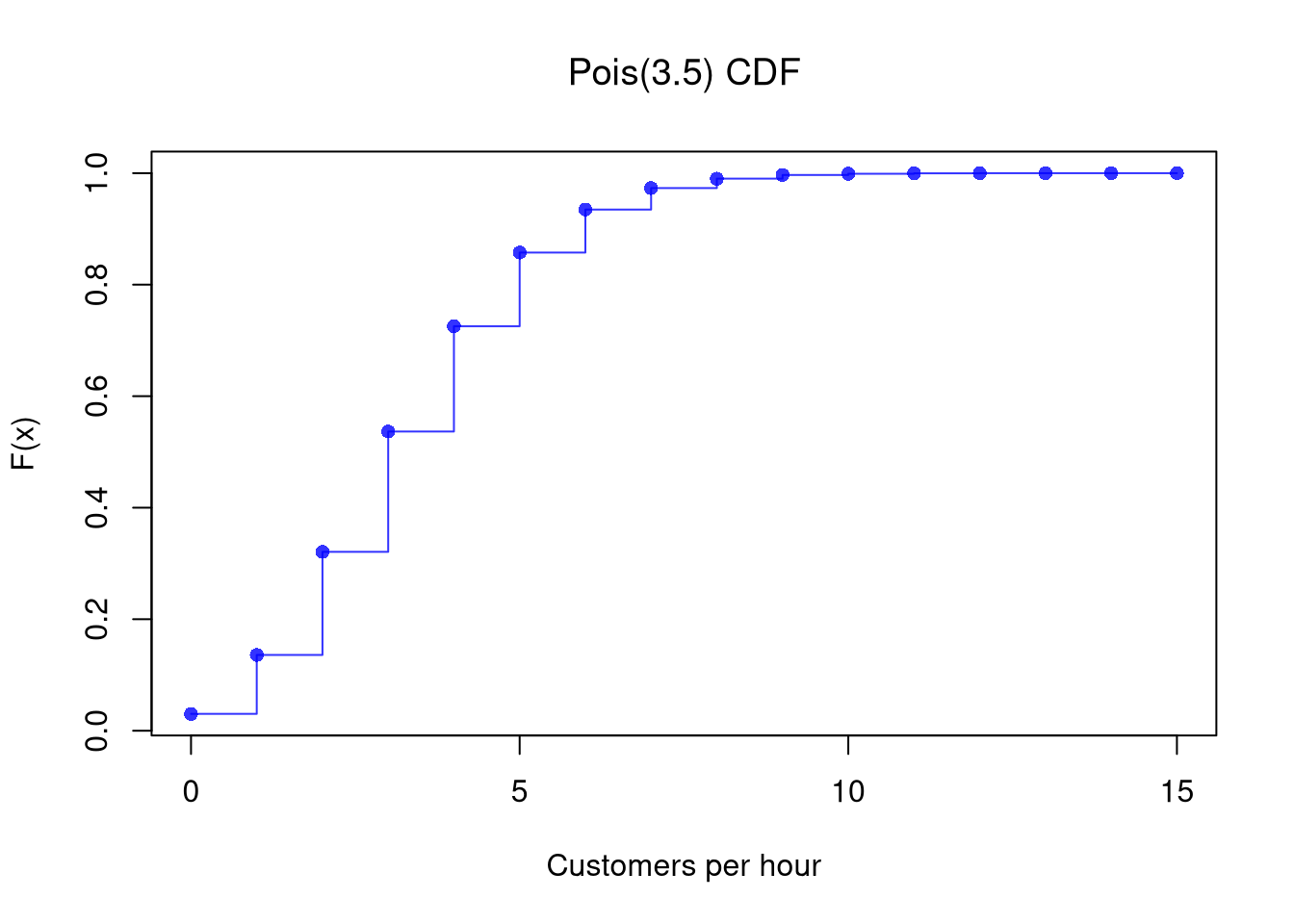
# CDF plot
F_x <- ppois(x, lambda)
plot(x, F_x, type='s', col=rgb(0, 0, 1, .8),
xlab = 'Customers per hour', ylab = 'F(x)', main=NA)
points(x, F_x, pch=16, col=rgb(0, 0, 1, .8))
title(bquote(paste('Pois(', .(lambda), ') CDF')), font.main=1)
Show that \(\mathbb{E}[X_{i}] = \mathbb{V}[X_{i}]= \lambda\). That is, the Poisson mean and variance are both equal to the rate parameter.
Code
# Compare empirical simulation vs theoretical
lambda <- 3.5
X <- rpois(1e4, lambda)
c(emp_mean = mean(X), th_mean = lambda)
## emp_mean th_mean
## 3.5111 3.5000
c(emp_var = var(X), th_var = lambda)
## emp_var th_var
## 3.420019 3.500000
During the lunch rush, the store averages \(\lambda=4.5\) customers per hour. What is the probability that more than \(7\) customers arrive in a given hour?
We need \(Prob(X_{i} > 7) = 1 - Prob(X_{i} \leq 7) = 1 - F(7)\). \[\begin{eqnarray}
Prob(X_{i} > 7) &=& 1 - \sum_{k=0}^{7} \frac{e^{-4.5} \cdot 4.5^{k}}{k!}
\end{eqnarray}\]
Code
# Prob(X > 7)
1 - ppois(7, lambda=4.5)
## [1] 0.08658647
# Verify: sum the PMF from 0 to 7
sum(dpois(0:7, lambda=4.5))
## [1] 0.9134135
There is roughly a \(9\%\) chance of more than \(7\) arrivals in a given hour.
The Poisson assumes the mean equals the variance. In real count data the variance is often larger than the mean (called overdispersion), because real-world arrivals are bunchier than the Poisson assumes. Before using a Poisson, compute the ratio \(\text{var}(x)/\text{mean}(x)\) on the data; a ratio well above \(1\) is a warning sign.
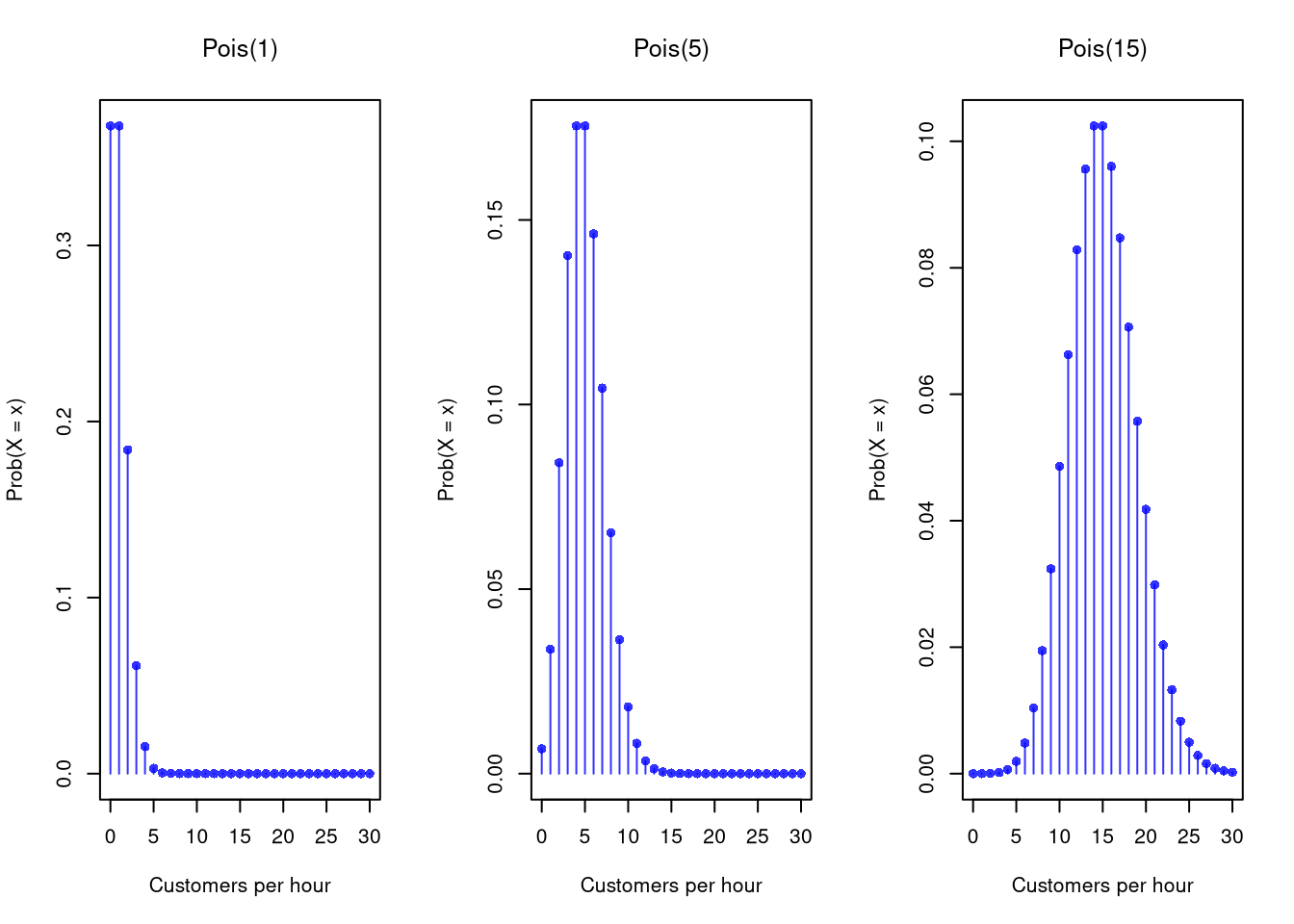
The shape of the Poisson also changes with \(\lambda\). A quiet specialty shop (\(\lambda=1\)) has a strongly right-skewed arrival pattern, while a busy supermarket (\(\lambda=15\)) looks nearly Normal.
Code
# Shape varies with lambda
par(mfrow=c(1, 3))
for(lam in c(1, 5, 15)) {
x <- seq(0, 30)
f_x <- dpois(x, lam)
plot(x, f_x, type='h', col=rgb(0, 0, 1, .8),
xlab = 'Customers per hour', ylab = 'Prob(X = x)', main=NA)
points(x, f_x, pch=16, col=rgb(0, 0, 1, .8))
title(bquote(paste('Pois(', .(lam), ')')), font.main=1)
}
Large Sample Approximations.
The de Moivre–Laplace Theorem says that as \(n\) grows large, with \(p \in (0,1)\) staying fixed, the Binomial distribution is approximately Normal with mean \(np\) and variance \(np(1-p)\)
The unemployment rate is \(10%\). Suppose that \(100\) employable people are selected randomly. What is the probability that this sample contains between \(9\) and \(12\) unemployed people. Use the normal approximation to binomial probabilities.
Parameters are \[\begin{eqnarray}
\mu &\approx& n p = 10 \\
\sigma^2 &=& n p (1−p) = 100 (0.1)(0.9)=9 \\
\sigma &=& \sqrt{9}=3.
\end{eqnarray}\]
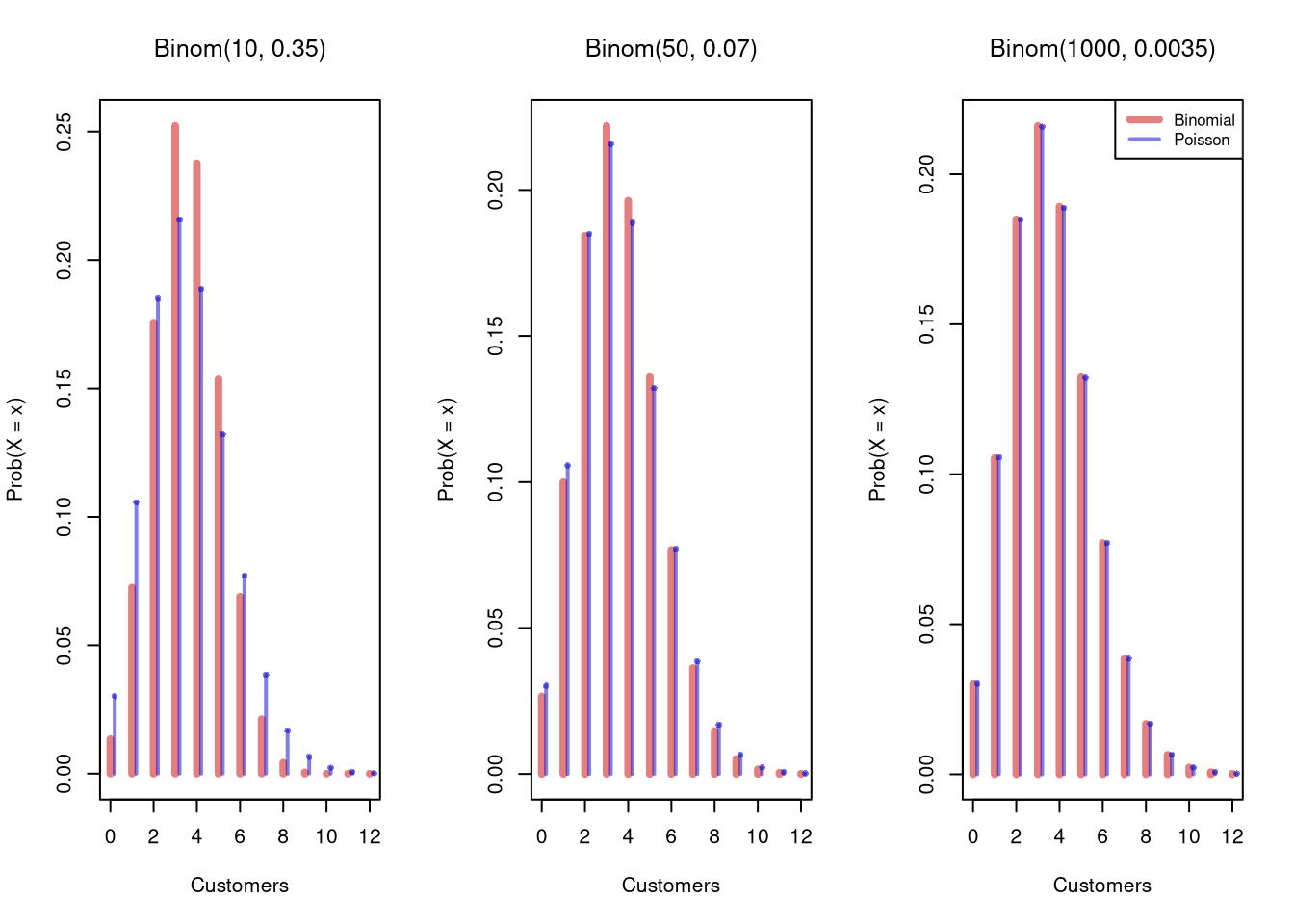
The Poisson Limit Theorem says that as \(n\) grows large, with \(p\) growing smaller at the same time, and \(n p\) converging to a fixed number \(\lambda\), the Binomial distribution is approximately Poisson with parameter \(\lambda\).
Imagine dividing one hour into \(n\) tiny intervals. If the store averages \(\lambda = 3.5\) customers per hour, each interval has a small probability \(p = \lambda/n = 3.5/n\) of an arrival. With \(n\) independent intervals, the number of arrivals is Binomial: \[Prob(X=x) = \binom{n}{x} \left(\frac{\lambda}{n}\right)^{x} \left(1-\frac{\lambda}{n}\right)^{n-x}\]
As \(n\) grows large, three things happen:
- \(\binom{n}{x} \cdot \frac{1}{n^{x}} \to \frac{1}{x!}\), because \(\binom{n}{x} = \frac{n(n-1)\cdots(n-x+1)}{x!}\) and each factor in the numerator is approximately \(n\)
- \(\left(1 - \frac{\lambda}{n}\right)^{n} \to e^{-\lambda}\), by the definition of \(e\)
- \(\left(1 - \frac{\lambda}{n}\right)^{-x} \to 1\), since \(x\) is fixed and \(\lambda/n \to 0\)
Multiplying the pieces together: \(\frac{1}{x!} \cdot \lambda^{x} \cdot e^{-\lambda} = e^{-\lambda}\lambda^{x}/x!\), which is the Poisson PMF. In other words, the Poisson is what the Binomial becomes when there are many opportunities for an event but each one is individually unlikely (see also Large Sample Approximations below).
Code
# Binomial approaches Poisson as n grows
lambda <- 3.5
x <- seq(0, 12)
f_pois <- dpois(x, lambda)
par(mfrow=c(1, 3))
for(n in c(10, 50, 1000)) {
f_binom <- dbinom(x, size=n, prob=lambda/n)
comp_cols <- c(rgb(.8, 0, 0, .5), rgb(0, 0, .8, .5))
plot(x, f_binom, type='h', col=comp_cols[1], lwd=4,
xlab='Customers', ylab='Prob(X = x)', main=NA)
points(x + 0.2, f_pois, type='h', col=comp_cols[2], lwd=2)
points(x + 0.2, f_pois, pch=16, col=comp_cols[2], cex=0.7)
title(bquote(paste('Binom(', .(n), ', ', .(round(lambda/n, 4)), ')')), font.main=1)
}
legend('topright', c('Binomial', 'Poisson'),
col=comp_cols, lwd=c(4, 2), cex=0.8)
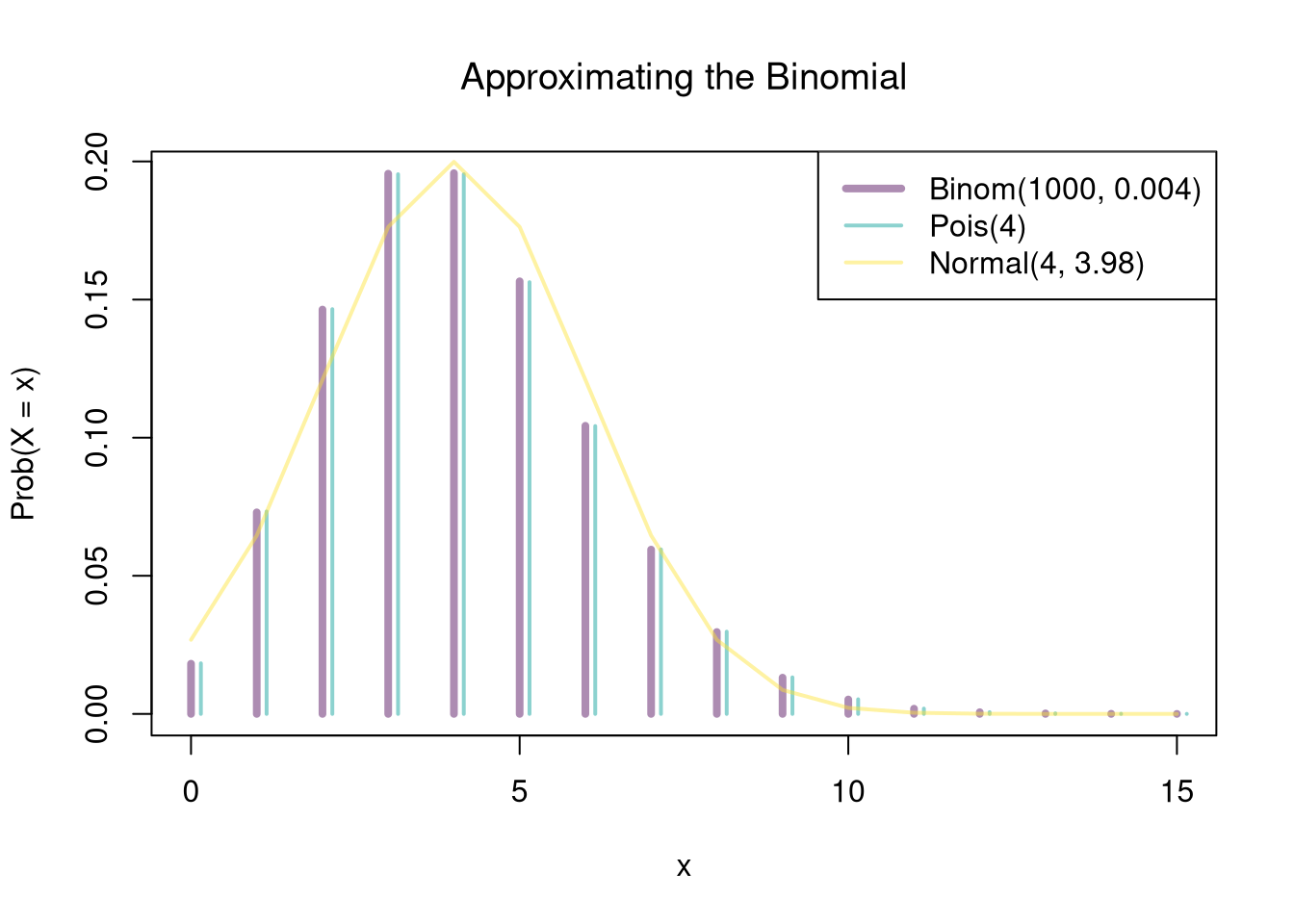
For another example, consider \(n=1000\) independent trials each with probability \(p=0.004\), so \(\lambda = np = 4\). We can compare the exact Binomial to both approximations at once: the Poisson (\(\lambda=4\)) and the Normal (\(\mu=np=4\), \(\sigma^{2}=np(1-p)\approx 3.98\)).
Code
# Binom(1000, 0.004) vs Pois(4) vs Normal(4, 3.98)
n <- 1000
p <- 0.004
x <- seq(0, 15)
f_binom <- dbinom(x, size=n, prob=p)
f_pois <- dpois(x, lambda=n*p)
f_norm <- dnorm(x, mean=n*p, sd=sqrt(n*p*(1-p)))
approx_cols <- hcl.colors(3, alpha=.45)
plot(x, f_binom, type='h', col=approx_cols[1], lwd=4,
xlab='x', ylab='Prob(X = x)',
main=NA)
title('Approximating the Binomial', font.main=1)
points(x + 0.15, f_pois, type='h', col=approx_cols[2], lwd=2)
lines(x, f_norm, col=approx_cols[3], lwd=2)
legend('topright',
c('Binom(1000, 0.004)', 'Pois(4)', 'Normal(4, 3.98)'),
col=approx_cols, lwd=c(4, 2, 2))
The Poisson is nearly exact here because \(p\) is very small. The Normal is a rougher fit because \(\lambda=4\) is still fairly small and the distribution is noticeably skewed. As \(\lambda\) grows, the Poisson itself becomes more symmetric and the Normal approximation improves.